14-mal heruntergeladen












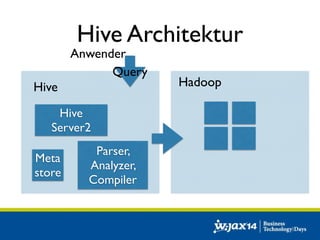


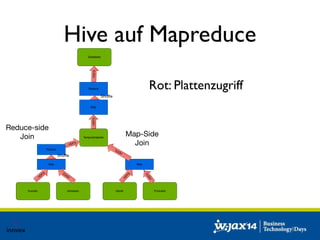

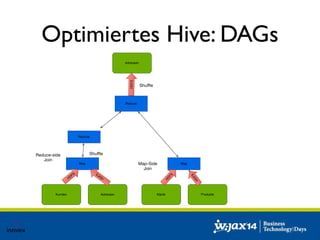

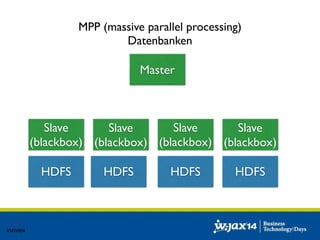

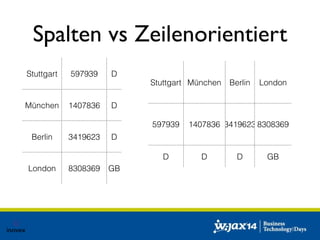










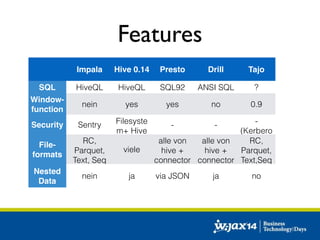
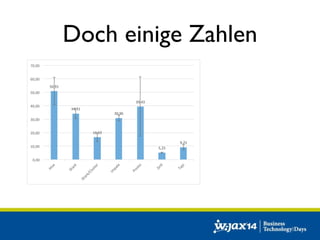
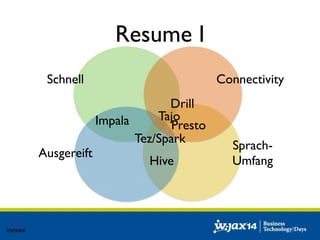




Das Dokument diskutiert die Entwicklung von SQL-Lösungen im Hadoop-Umfeld und untersucht verschiedene SQL-Engines wie Hive, Presto und Impala, die auf unterschiedliche Anwendungsfälle abzielen. Es behandelt auch Optimierungsmöglichkeiten für Hive und die Integration mit anderen Datenquellen, wobei die Entscheidung für eine spezifische Technologie von den individuellen Anforderungen abhängt. Abschließend wird auf die dynamische Natur des Big Data Marktes hingewiesen, die eine maßgeschneiderte Evaluierung der Lösungen notwendig macht.
























































