Downloaden Sie, um offline zu lesen






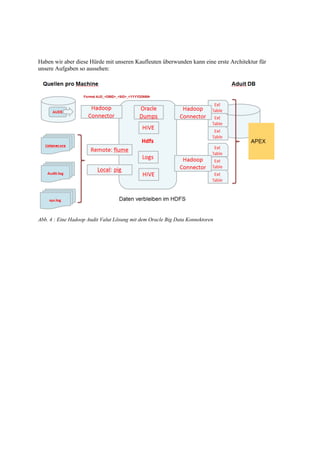


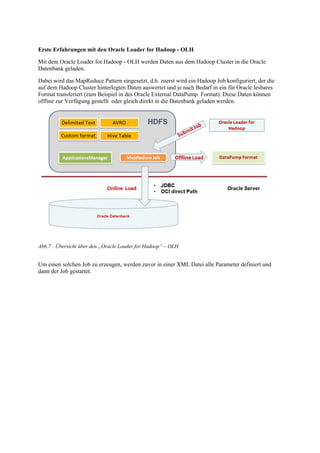
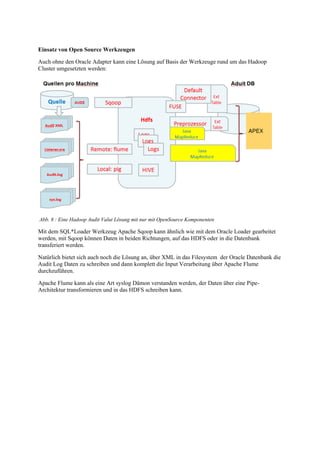




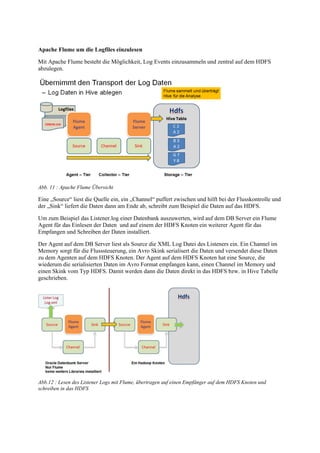


Der Vortrag von Gunther Pippèrr behandelt die Integration der Oracle-Datenbank in das Hadoop- und NoSQL-Ökosystem, um die Archivierung und Analyse großer Datenmengen zu optimieren. Es werden verschiedene Architekturansätze zur Verknüpfung der Oracle RDBMS mit Hadoop vorgestellt, um sowohl strukturierte als auch unstrukturierte Daten effektiv zu verarbeiten und die Kosten für Hardware und Lizenzen zu minimieren. Die Nutzung des Apache Hadoop Ökosystems wird als zukunftsorientierte Lösung hervorgehoben, um den wachsenden Anforderungen an Datenverarbeitung und -archivierung gerecht zu werden.


























































