Downloaden Sie, um offline zu lesen

















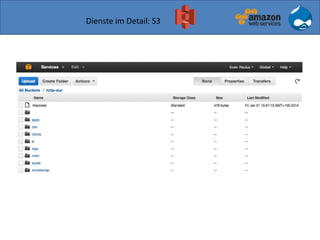

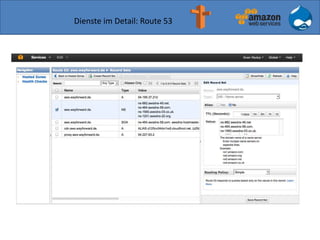



![Einschub: Wie fester Hostname bei wechselnder IP?
• Route 53 to the rescue
#! /bin/sh
export AWS_USER=drupal
export AWS_ACCESS_KEY_ID="<IDENTIFIER_DES_SCHLUESSELS>"
export AWS_SECRET_ACCESS_KEY="<GEHEIMER_KEY>"
PUBLIC_IP=`ec2metadata | awk '/^public-ipv4/{print $2}'`
/usr/local/bin/cli53 rrcreate aws.wayforward.de '' A
$PUBLIC_IP --ttl 60 --replace
echo "Updated aws.wayforward.de to $PUBLIC_IP - $?"
echo "$PUBLIC_IP" | mail -s "[AWS] aws.wayforward.de is
now at $PUBLIC_IP" sven@karlsruhe.org
mit https://github.com/barnybug/cli53](https://image.slidesharecdn.com/drupal-aws-2014-04-08-3-140407152203-phpapp02/85/Drupal-7-auf-Amazon-Web-Services-28-320.jpg)
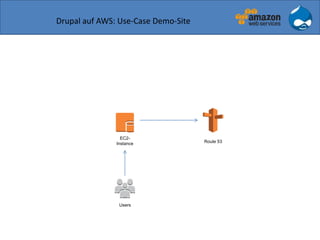

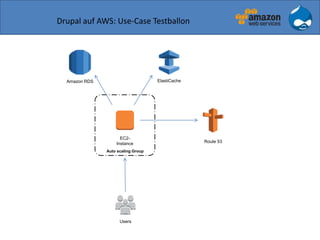

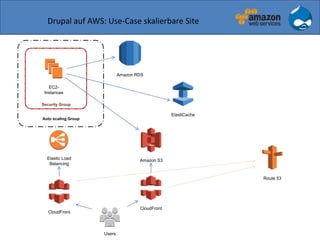






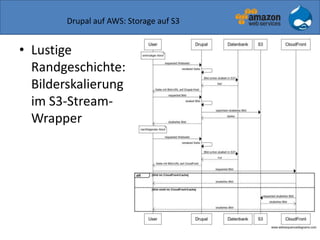









Der Vortrag von Sven Paulus beleuchtet die Vorteile von Drupal 7 auf Amazon Web Services (AWS), darunter Flexibilität, Skalierbarkeit und Kostentransparenz. Er erläutert verschiedene AWS-Dienste wie EC2, S3 und Route 53, die zur Bereitstellung und Verwaltung von Drupal-Anwendungen verwendet werden können, sowie Beispiele für verschiedene Nutzungsszenarien. Abschließend wird die Integration von Drupal mit AWS diskutiert, wobei mögliche Herausforderungen und Lösungsvorschläge aufgeführt werden.

















































