Downloaden Sie, um offline zu lesen









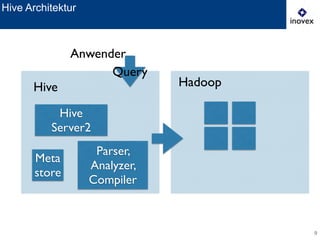


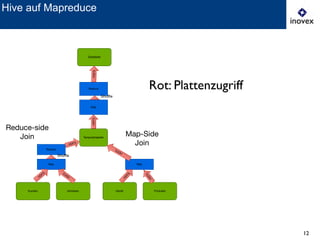
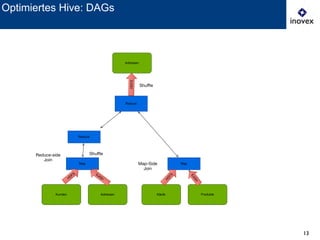

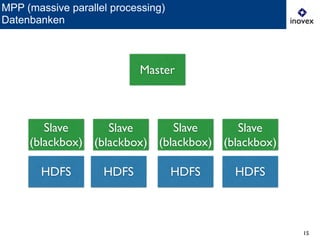








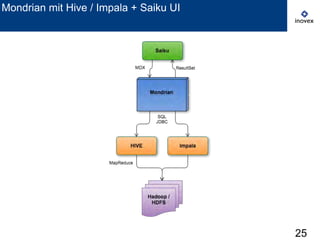
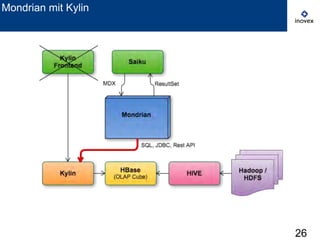
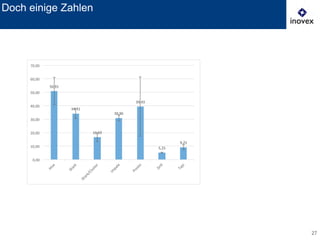



Das Dokument behandelt die Verwendung von SQL auf Hadoop für Business Intelligence im Kontext von Big Data und bietet einen Überblick über verschiedene SQL-Engines wie Hive, Presto und Impala. Es wird dargelegt, warum SQL trotz der Präsenz von NoSQL-Lösungen relevant bleibt und diskutiert die Architektur und Optimierungsmöglichkeiten von Hive sowie neue Entwicklungen und Herausforderungen in diesem Bereich. Die Präsentation schließt mit der Erkenntnis, dass es momentan keine universelle Lösung gibt und dass die Auswahl von Technologien von den spezifischen Anwendungsfällen abhängt.























































