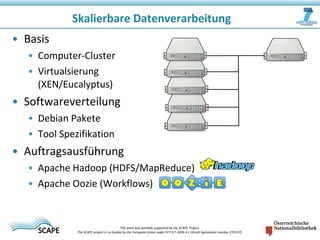
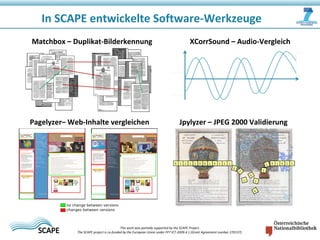
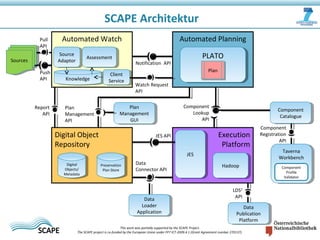
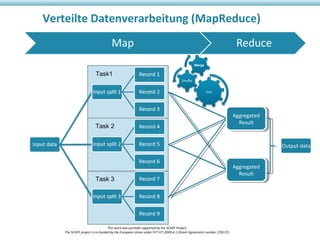
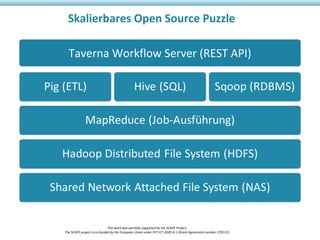
Das Dokument beschreibt das SCAPE-Projekt zur skalierbaren Langzeitarchivierung großer Datenmengen, welches von der EU gefördert wird. Es behandelt verschiedene Lösungen und Werkzeuge für die effiziente Verwaltung, Speicherung und Analyse von Daten in Bibliotheken und Repositories. Zudem werden technische Aspekte der Datenverarbeitung und konkrete Anwendungsfälle angesprochen.