Als PDF, PPTX herunterladen








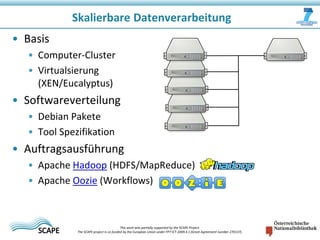

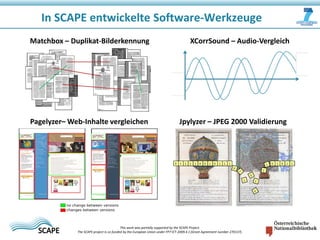


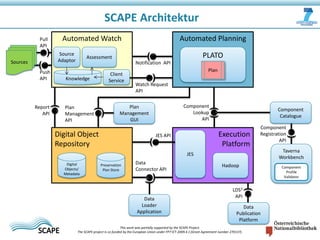




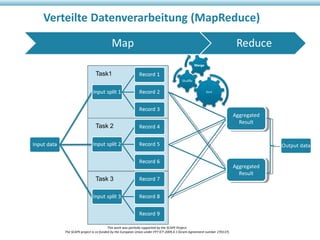
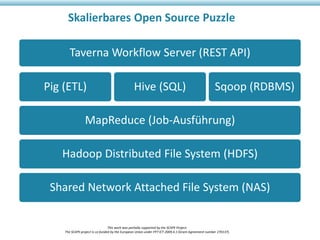










Das Dokument beschreibt das SCAPE-Projekt, das sich mit skalierbarer Langzeitarchivierung großer Datenmengen beschäftigt, unterstützt von der Europäischen Union. Es werden Lösungen und Werkzeuge zur Verwaltung, Analyse und Archivierung digitaler Inhalte sowie spezifische Anwendungsfälle in Bibliotheken und Datenzentren vorgestellt. Zudem werden die technischen Grundlagen und Konzepte wie Hadoop und verteilte Datenverarbeitung erläutert.















































