Als PDF, PPTX herunterladen





















![Word Count - Spark_
35
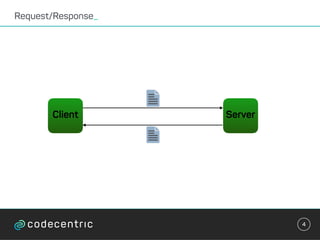
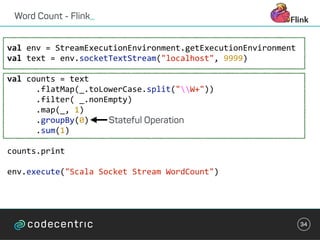
val sparkConf =
new SparkConf().setAppName("Streaming Word Count")
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint(".")
val mappingFunc = (key: String, value: Option[Int], state:
State[Int]) => {
val sum = value.getOrElse(0) + state.getOption.getOrElse(0)
val output = (key, sum)
state.update(sum)
output
}
val wordCountState = StateSpec.function(mappingFunc)](https://image.slidesharecdn.com/streaminguberblick-161123111026/85/Streaming-Plattformen-und-die-Qual-der-Wahl-35-320.jpg)




![Word Count - Samza_
43
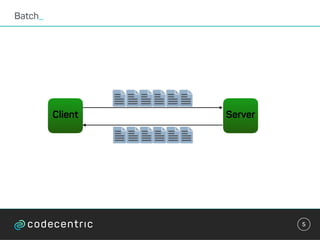
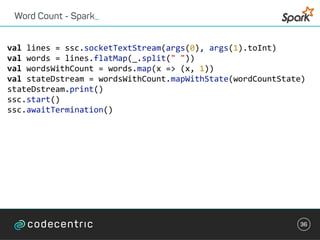
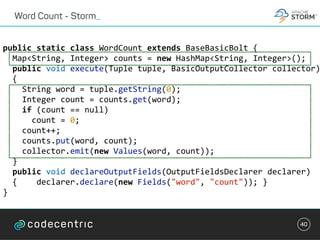
class WordCountTask extends StreamTask with InitableTask {
private var store: CountStore = _
def init(config: Config, context: TaskContext) {
this.store = context.getStore("wordcount-store")
.asInstanceOf[KeyValueStore[String, Integer]]
}](https://image.slidesharecdn.com/streaminguberblick-161123111026/85/Streaming-Plattformen-und-die-Qual-der-Wahl-43-320.jpg)
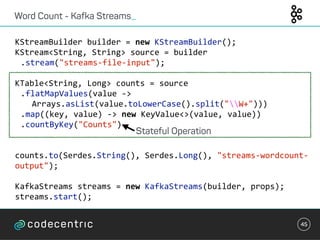
![Word Count - Samza_
44
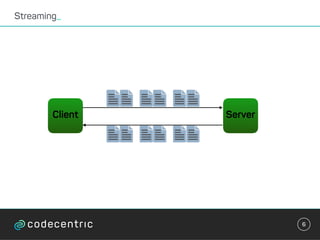
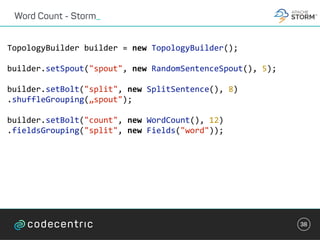
override def process(envelope: IncomingMessageEnvelope,
collector: MessageCollector, coordinator: TaskCoordinator) {
val words = envelope.getMessage.asInstanceOf[String].split(" ")
words.foreach { key =>
val count: Integer = Option(store.get(key)).getOrElse(0)
store.put(key, count + 1)
collector.send(new OutgoingMessageEnvelope(new
SystemStream("kafka", "wordcount"),
(key, count)))
}
}](https://image.slidesharecdn.com/streaminguberblick-161123111026/85/Streaming-Plattformen-und-die-Qual-der-Wahl-44-320.jpg)
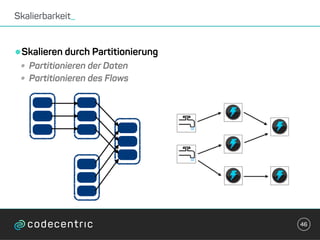
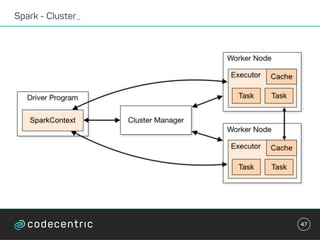
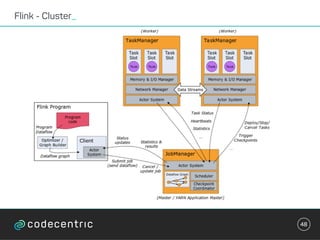

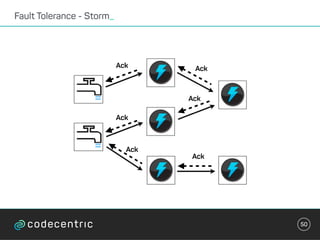
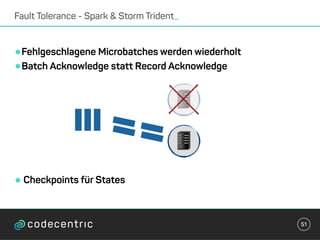
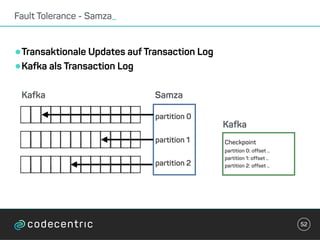
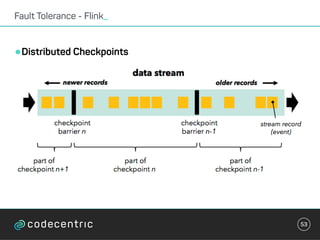
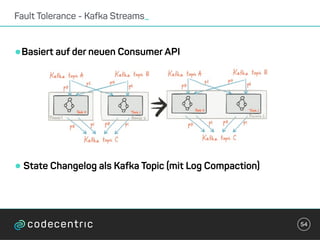

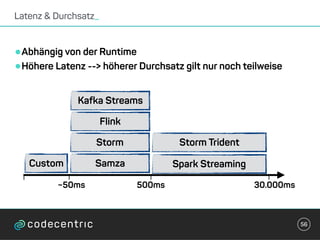
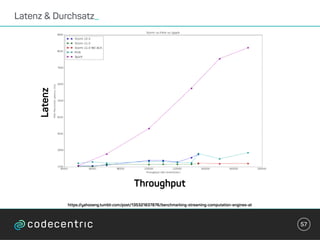


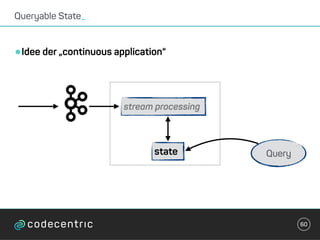


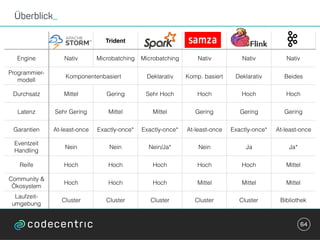





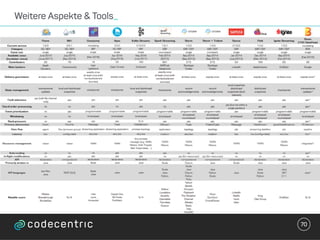








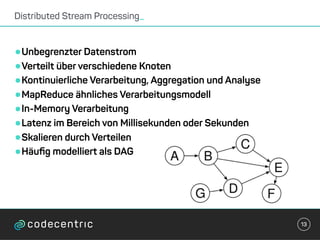
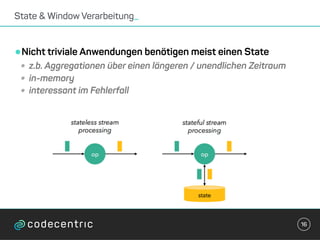
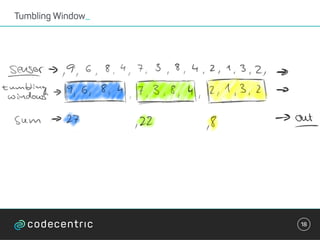
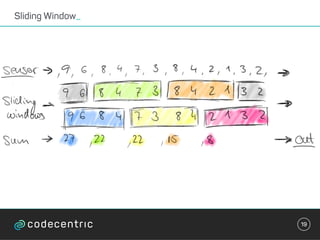
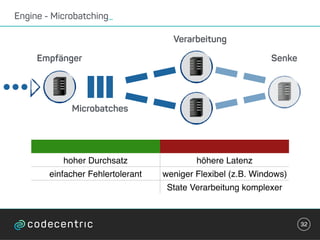
Der Vortrag behandelt grundlegende Konzepte und Auswahlkriterien für Stream Processing Plattformen sowie verschiedene Frameworks wie Apache Storm, Spark Streaming und Flink. Es werden Techniken zur Verarbeitung unendlicher Datenströme, die Unterschiede zwischen Event- und Verarbeitungszeit, und Strategien für Zustandsverwaltung und Fehlertoleranz erläutert. Zudem werden Empfehlungen für den Einsatz bestimmter Technologien gegeben, je nach Anforderungen an Latenz, Durchsatz und Community-Support.

























