Downloaden Sie, um offline zu lesen






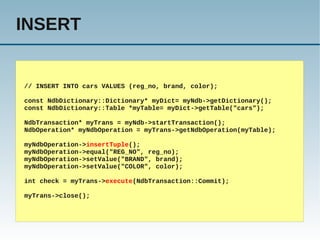
![SELECT
# SELECT * FROM test.test where id = 42;
use Net::HandlerSocket;
my $args = { host => 'master', port => 9998 };
my $hs = new Net::HandlerSocket($args);
my $res = $hs->open_index(0, 'test', 'test', 'PRIMARY', 'id,data,ts');
$res = $hs->execute_single(0, '=', [ '42' ], 1, 0);
shift(@$res);
for (my $row = 0; $row < 1; ++$row) {
print "$idt$datat$tsn";
}
$hs->close();](https://image.slidesharecdn.com/mysqlnosqlinternetbriefing2011-120207101802-phpapp02/85/Internet-Briefing-2011-NoSQL-with-MySQL-10-320.jpg)



![SELECT
// SELECT * FROM cars;
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("cars");
myTrans = myNdb->startTransaction();
myScanOp = myTrans->getNdbScanOperation(myTable);
myScanOp->readTuples(NdbOperation::LM_CommittedRead)
myRecAttr[0] = myScanOp->getValue("REG_NO");
myRecAttr[1] = myScanOp->getValue("BRAND");
myRecAttr[2] = myScanOp->getValue("COLOR");
myTrans->execute(NdbTransaction::NoCommit);
while ((check = myScanOp->nextResult(true)) == 0) {
std::cout << myRecAttr[0]->u_32_value() << "t";
std::cout << myRecAttr[1]->aRef() << "t";
std::cout << myRecAttr[2]->aRef() << std::endl;
}
myNdb->closeTransaction(myTrans);](https://image.slidesharecdn.com/mysqlnosqlinternetbriefing2011-120207101802-phpapp02/85/Internet-Briefing-2011-NoSQL-with-MySQL-16-320.jpg)



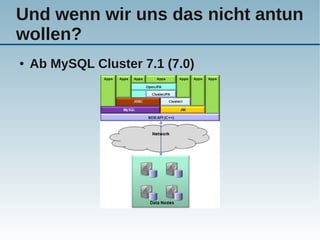
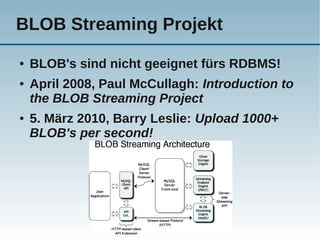


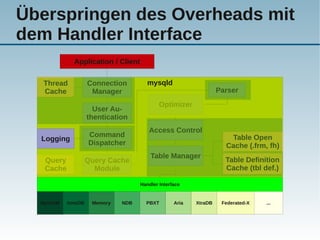










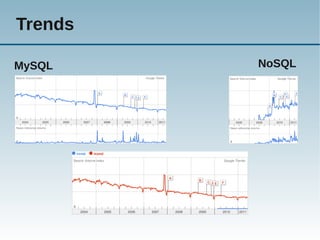
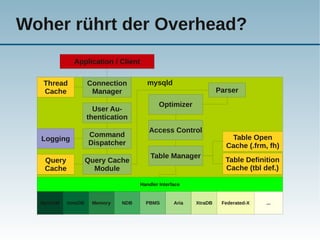
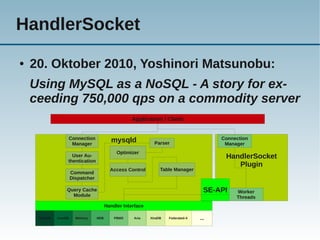
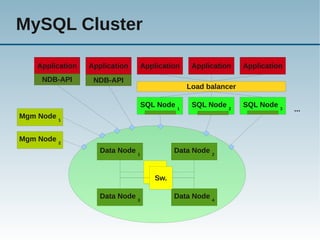
Das Dokument behandelt die Nutzung von NoSQL-Technologien in Verbindung mit MySQL, insbesondere die HandlerSocket- und NDB-API, um die Effizienz von einfachen Abfragen zu steigern und den SQL-Overhead zu reduzieren. Es wird erläutert, wie alternative Abfragemuster und verschiedene Technologien die Leistung von MySQL erheblich verbessern können, während gleichzeitig Bedenken über die Komplexität der Architektur und Programmierung geäußert werden. Abschließend wird darauf hingewiesen, dass SQL gut für komplexe Abfragen geeignet ist, während NoSQL typischerweise für einfache Abfragen verwendet wird.

































































