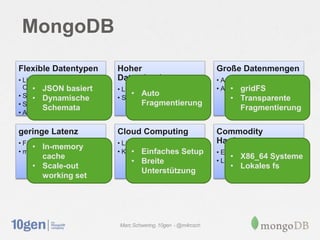
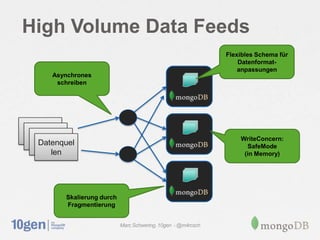
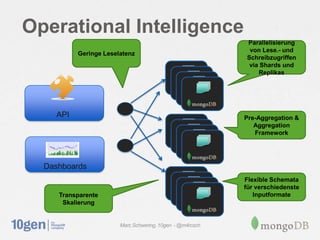
Das Dokument behandelt die Anwendungsfälle von MongoDB, einschließlich der Flexibilität von Datentypen, der Verwaltung hoher Datemengen und der Unterstützung agiler Entwicklungsprozesse durch niedrige Latenzen und Cloud-Computing. Es werden verschiedene Einsatzzwecke wie Hochfrequenzhandel, soziale Medien und Operationsintelligenz diskutiert, wobei die Fähigkeit zur dynamischen Schema-Anpassung und Skalierung hervorgehoben wird. Abschließend wird auf die Eignung von MongoDB für variable Datenmodelle und die Vorteile von Sharding und Replikation eingegangen.







![Beispiel Tracking &
Conversion
Umfangreiches
Schema um komplexe
Stati abzubilden
1 See Ad
{ cookie_id: ‚1234512413243‛,
“Scale out” für hohen
advertiser:{
Datendurchsatz apple: {
See Ad actions: [
2 { impression: ‘ad1’, time: 123 },
{ impression: ‘ad2’, time: 232 },
{ click: ‘ad2’, time: 235 },
{ add_to_cart: ‘laptop’,
sku: ‘asdf23f’,
time: 254 },
3 Click { purchase: ‘laptop’, time: 354 }
Dynamische ] …
Schemata durch
Kundenanforderunge
n
4 Convert
Marc Schwering, 10gen - @m4rcsch](https://image.slidesharecdn.com/2-1germancommonusecases-130211103442-phpapp01/85/Webinar-Typische-MongoDB-Anwendungsfalle-Common-MongoDB-Use-Cases-10-320.jpg)



![Content Management
Flexibles Schema für GeoSpatial Index
GridFS für Binärdaten einfache
Erweiterungen
{ camera: ‚Nikon d4‛,
location: [ -122.418333, 37.775 ]
}
{ camera: ‚Canon 5d mkII‛,
people: [ ‚Jim‛, ‚Carol‛ ],
taken_on: ISODate("2012-03-07T18:32:35.002Z")
}
{ origin: ‚facebook.com/photos/xwdf23fsdf‛,
license: ‚Creative Commons CC0‛,
size: {
dimensions: [ 124, 52 ],
Horizontale units: ‚pixels‛
}
Skalierbarkeit für
}
große Datensätze
Marc Schwering, 10gen - @m4rcsch](https://image.slidesharecdn.com/2-1germancommonusecases-130211103442-phpapp01/85/Webinar-Typische-MongoDB-Anwendungsfalle-Common-MongoDB-Use-Cases-14-320.jpg)

















































