Downloaden Sie, um offline zu lesen




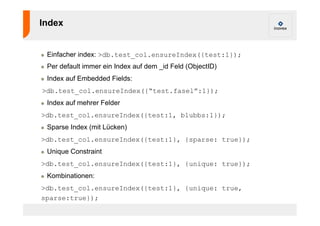


![Anwendung – Geo Daten
>db.places.insert({loc: {lat: 50, lon: 50}})
>db.places.ensureIndex( { loc : "2d" } , { bits : 26 } )
>db.places.find( { loc : { $near : [50,50] ,
$maxDistance : 5 } } ).limit(20)
Placemark Server ohne eine Zeile Code!](https://image.slidesharecdn.com/mongodb-nils-domrose-08-2014-140825080334-phpapp02/85/mongoDB-im-Einsatz-Grundlagen-14-320.jpg)
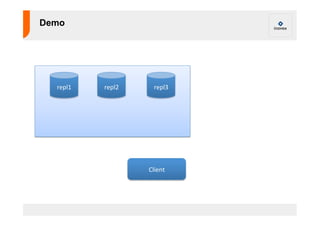


Das Dokument beschreibt die Grundlagen und Vorteile von MongoDB, einer dokumentenorientierten Datenbank, die für hohe Verfügbarkeit und Skalierbarkeit entwickelt wurde. Es erläutert Funktionen wie Schemafreiheit, Indizierung und Sharding sowie Anwendungsbeispiele für Echtzeit-Statistiken und Logging. Zudem werden wichtige Installationshinweise und typische Anwendungsfälle vorgestellt, um die Effizienz und Flexibilität von MongoDB zu demonstrieren.






























































