






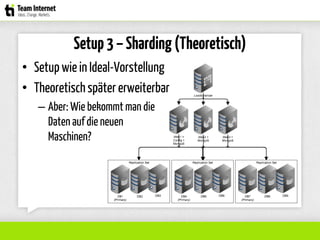




















Das Dokument beschreibt die Erfahrungen und Herausforderungen der Autoren mit der Skalierung von MongoDB auf echtem Hardware und in der Cloud (Amazon EC2). Es behandelt Themen wie Performance-Tuning, Sharding, High Availability und Backup-Strategien und vermittelt wichtige Erkenntnisse zur Optimierung der Datenbankarchitektur. Die Autoren geben wertvolle Tipps zur Handhabung von Lese- und Schreiblasten sowie zur Planung von Replikations- und Sharding-Setups.


























