Das Dokument bietet eine umfassende Einführung in Elasticsearch, einschließlich Installation, Indizierung und Suchanfragen über HTTP und Java. Es behandelt Themen wie Aggregationen, zentralisiertes Logging und die Architektur von Elasticsearch-Clustern, einschließlich Sharding und Replikation. Zudem werden spezifische Inhalte und Beispiele für die Nutzung von Elasticsearch vorgestellt.





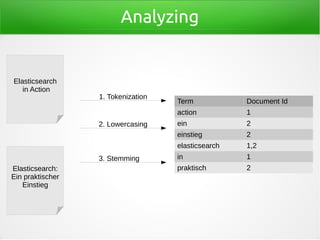
![Indizierung
curl -XPOST "http://localhost:9200/library/book" -d'
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}'](https://image.slidesharecdn.com/einfuehrung-in-elasticsearch-151009033527-lva1-app6892/85/Einfuhrung-in-Elasticsearch-6-320.jpg)
![Suche
curl -XPOST "http://localhost:9200/library/book/_search
?q=elasticsearch"
{
[...]
"hits": {
"hits": [
{
"_index": "library",
"_type": "book",
"_source": {
"title": "Elasticsearch in Action",
[...]](https://image.slidesharecdn.com/einfuehrung-in-elasticsearch-151009033527-lva1-app6892/85/Einfuhrung-in-Elasticsearch-7-320.jpg)

![Sprachspezifische Inhalte
curl -XPOST "http://localhost:9200/library/book/" -d'
{
"title": "Elasticsearch - Ein praktischer Einstieg",
"author": "Florian Hopf",
"published": "2015-10-26T00:00:00.000Z",
"publisher": {
"name": "dpunkt.verlag",
"country": "DE"
},
"tags": ["Lucene", "Elasticsearch"]
}'](https://image.slidesharecdn.com/einfuehrung-in-elasticsearch-151009033527-lva1-app6892/85/Einfuhrung-in-Elasticsearch-9-320.jpg)
































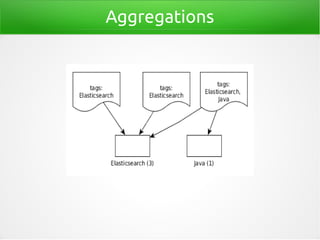


![Terms-Aggregation
"aggregations": {
"common-tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Elasticsearch",
"doc_count": 2
},
{
"key": "Lucene",
"doc_count": 2
},
{
"key": "Java",
"doc_count": 1
}]
[...]](https://image.slidesharecdn.com/einfuehrung-in-elasticsearch-151009033527-lva1-app6892/85/Einfuhrung-in-Elasticsearch-47-320.jpg)


![Aggregationen kombinieren
"buckets": [
{
"key": "Elasticsearch",
"doc_count": 2,
"published": {
"buckets": [
{
"key_as_string": "2015-10-
01T00:00:00.000Z",
"key": 1443657600000,
"doc_count": 2
}
]
}
},
[...]](https://image.slidesharecdn.com/einfuehrung-in-elasticsearch-151009033527-lva1-app6892/85/Einfuhrung-in-Elasticsearch-50-320.jpg)







































































