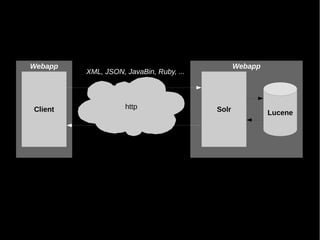
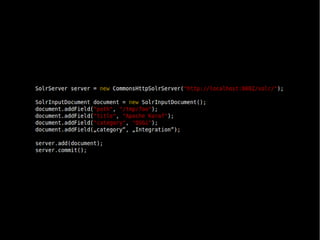
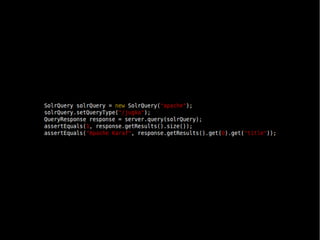
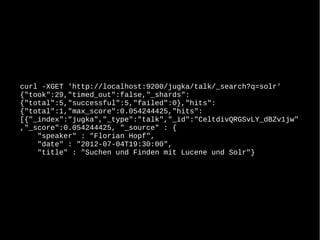
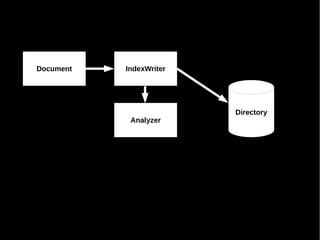
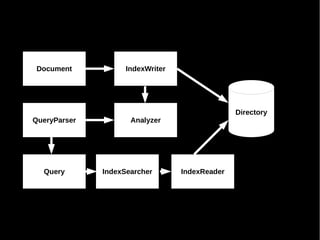
Das Dokument behandelt die Nutzung von Lucene und Solr zur Durchführung von Suchanfragen und die Verwaltung von Indexen. Es enthält Beispiele für SQL-Abfragen, Tokenisierung, Analyzer-Konfiguration sowie verschiedene Anfragetypen und deren Handhabung in einem Suchserver. Zudem werden eine Vielzahl von Funktionen, wie geospatial search, fuzzy queries und die Integration von APIs besprochen.


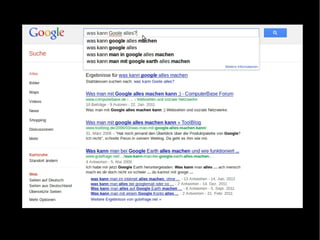







![File directory = new File(dir);
File[] textFiles = directory.listFiles(new TextFiles());
for (File probableMatch : textFiles) {
String text = readText(probableMatch);
if (text.matches(".*" + Pattern.quote(term) + ".*")) {
filesWithMatches.add(probableMatch.getAbsolutePath());
}
}](https://image.slidesharecdn.com/lucene-solr-jugka-040712-120707031331-phpapp02/85/Lucene-Solr-talk-at-Java-User-Group-Karlsruhe-13-320.jpg)














![● WildcardQuery
● Integ*
● Te?t
● RangeQuery
● date:[20120705 TO 20121231]
● FuzzyQuery
● Schneyder~](https://image.slidesharecdn.com/lucene-solr-jugka-040712-120707031331-phpapp02/85/Lucene-Solr-talk-at-Java-User-Group-Karlsruhe-35-320.jpg)
![title:Apache AND speaker:schneyder~ AND date:[20120401 TO 20120430]](https://image.slidesharecdn.com/lucene-solr-jugka-040712-120707031331-phpapp02/85/Lucene-Solr-talk-at-Java-User-Group-Karlsruhe-36-320.jpg)
![title:Apache AND speaker:schneyder~ AND date:[20120401 TO 20120430]
BooleanQuery
AND
TermQuery FuzzyQuery RangeQuery
title:apach speaker:schneyder date:[...]](https://image.slidesharecdn.com/lucene-solr-jugka-040712-120707031331-phpapp02/85/Lucene-Solr-talk-at-Java-User-Group-Karlsruhe-37-320.jpg)
![title:Apache AND speaker:schneyder~ AND date:[20120401 TO 20120430]
BooleanQuery
AND
TermQuery FuzzyQuery RangeQuery
title:apach speaker:schneyder date:[...]](https://image.slidesharecdn.com/lucene-solr-jugka-040712-120707031331-phpapp02/85/Lucene-Solr-talk-at-Java-User-Group-Karlsruhe-38-320.jpg)