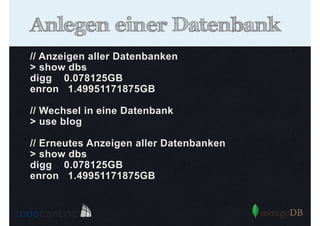
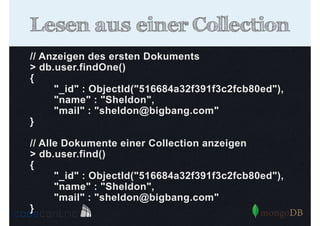
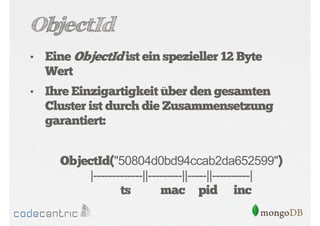
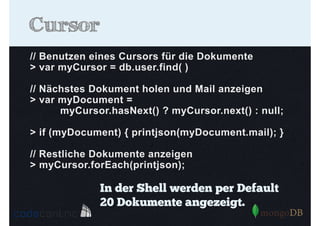
Als PDF, PPTX herunterladen




























![Flexibles Schema
MongoDB
RDBMS
{
_id :
ObjectId("4c4ba5e5e8aabf3"),
employee_name: "Dunham, Justin",
department : "Marketing",
title : "Product Manager, Web",
report_up: "Neray, Graham",
pay_band: “C",
benefits : [
{ type : "Health",
plan : "PPO Plus" },
{ type :
"Dental",
plan : "Standard" }
]
}](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-33-320.jpg)









![Logische Verknüpfungen
// Oder-Verknüpfung
> db.user.find(
{$or : [ { name : “Sheldon“ },
{ mail : amy@bigbang.com }
]
})
// Und-Verknüpfung
> db.user.find(
{$and : [ { name : “Sheldon“ },
{ mail : amy@bigbang.com }
]
})](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-54-320.jpg)




![Hinzufügen zu Arrays
// Hinzufügen eines Arrays
> db.user.update( {name : “Sheldon“ },
{ $set : {enemies :
[ { name : “Wil Wheaton“ },
{ name : “Barry Kripke“ }
]
}})
// Hinzufügen eines Wertes zum Array
> db.user.update( { name : “Sheldon“},
{ $push : {enemies :
{ name : “Leslie Winkle“}
}})](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-59-320.jpg)





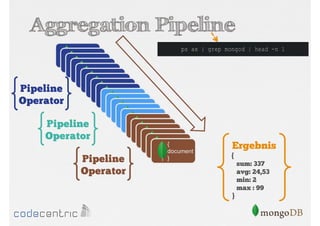



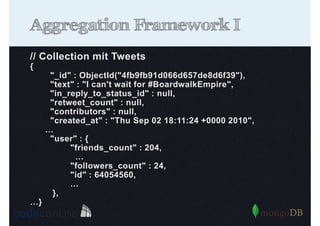

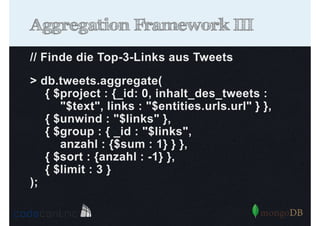






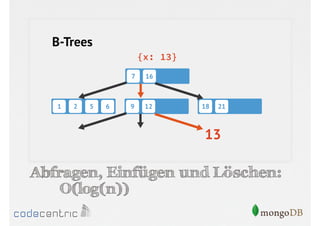

![Was kann indexiert werden?
// Mehrere Felder (Compound Key Indexes)
> db.recipes.ensureIndex({
main_ingredient: 1,
calories: -1
})
// Arrays mit Werten (Multikey Indexes)
{
name: 'Chicken Noodle Soup’,
ingredients : ['chicken', 'noodles']
}
> db.recipes.ensureIndex({ ingredients: 1 })](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-86-320.jpg)





![Geospatial Indexe
// Hinzufügen von Längen- und Breitengraden
{
name: ‚codecentric Frankfurt’,
loc: [ 50.11678, 8.67206]
}
// Indexierung der Koordinaten
> db.locations.ensureIndex( { loc : '2d' } )
// Abfrage nach Orten in der Nähe von codecentric Frankfurt
> db.locations.find({
loc: { $near: [ 50.1, 8.7 ] }
})](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-92-320.jpg)















![Indexe mit geringer
Selektivität
// Folgendes Feld hat nur sehr wenige eindeutige Werte
> db.collection.distinct('status’)
[ 'new', 'processed' ]
// Ein Index auf diesem Feld bringt nur sehr wenig
> db.collection.ensureIndex({ status: 1 })
> db.collection.find({ status: 'new' })
// Besser ist ein zusammengesetzter Index zusammen mit einem
// anderen Feld
> db.collection.ensureIndex({ status: 1, created_at: -1 })
> db.collection.find(
{ status: 'new' }
).sort({ created_at: -1 })](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-109-320.jpg)

![Negation
// Bei Negationen können Indexe nicht verwendet werden
> db.things.ensureIndex({ x: 1 })
// z.B. bei Abfragen mit not equal
> db.things.find({ x: { $ne: 3 } })
// …oder Abfragen mit not in
> db.things.find({ x: { $nin: [2, 3, 4 ] } })
// …oder Abfragen mit dem $not Operator
> db.people.find({ name: { $not: 'John Doe' } })](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-111-320.jpg)

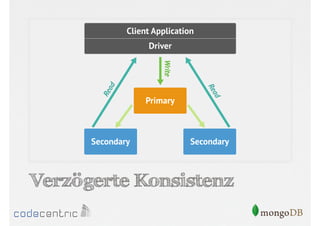

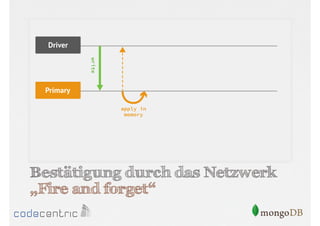
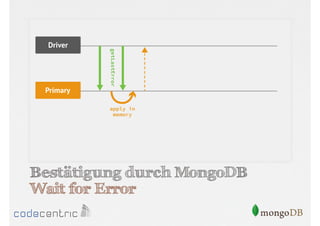
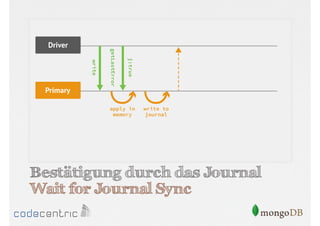
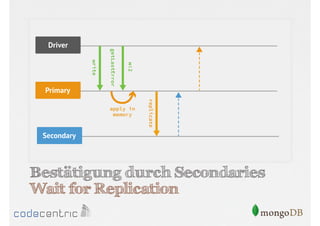

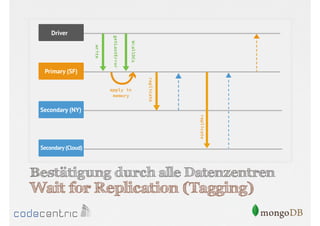
![Beispiel für Tagging
{
_id : "mySet",
members : [
{_id : 0, host : "A", tags : {"dc": "ny"}},
{_id : 1, host : "B", tags : {"dc": "ny"}},
{_id : 2, host : "C", tags : {"dc": "sf"}},
{_id : 3, host : "D", tags : {"dc": "sf"}},
{_id : 4, host : "E", tags : {"dc": "cloud"}}],
settings : {
getLastErrorModes : {
allDCs : {"dc" : 3},
someDCs : {"dc" : 2}} }
}
> db.blogs.insert({...})
> db.runCommand({getLastError : 1, w : "someDCs"})](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-121-320.jpg)


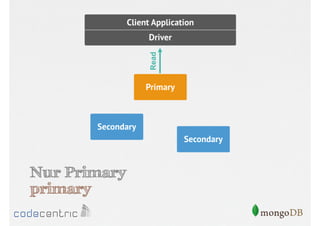
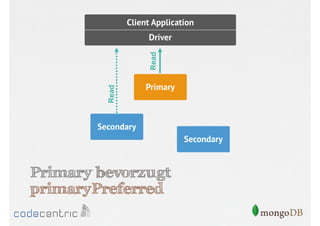
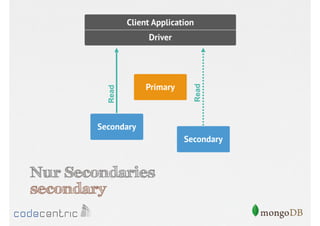
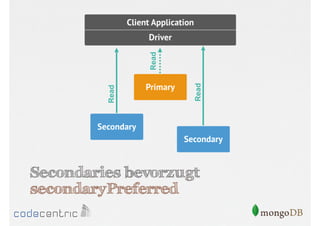
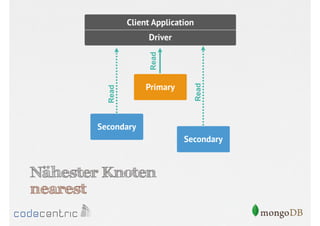

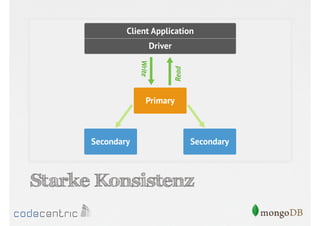
![Setzen der Read Preference
// Nur Primary
> cursor.setReadPref( “primary" )
// Primary bevorzugt
> cursor.setReadPref( “primaryPreferred" )
….
// Nur Secondaries mit Tagging
> cursor.setReadPref( “secondary“, [ rack : 2 ] )
Aufruf der Methode auf dem Cursor muss
vor dem Lesen der Dokumente erfolgen](https://image.slidesharecdn.com/mongodbfrjava-programmiererjavausergroupfrankfurt25-130926045418-phpapp02/85/MongoDB-fur-Java-Programmierer-131-320.jpg)

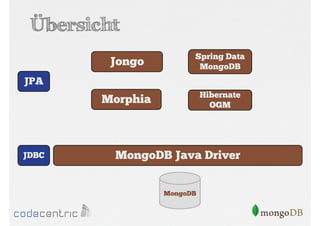



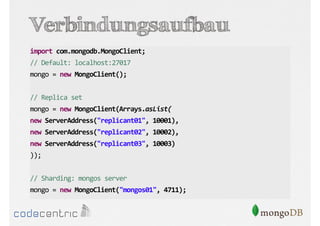
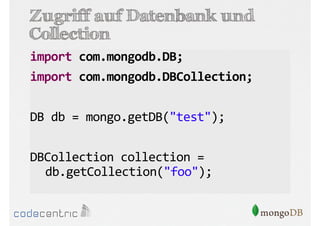
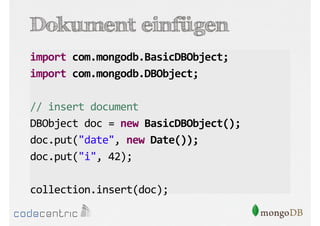
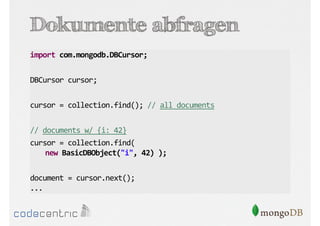











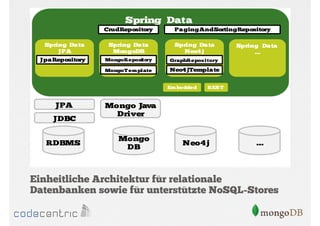

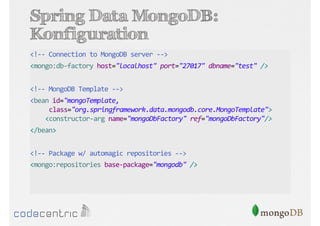
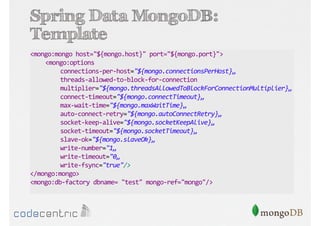
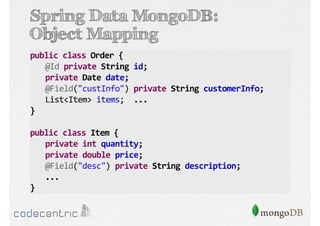





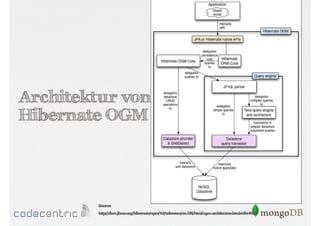







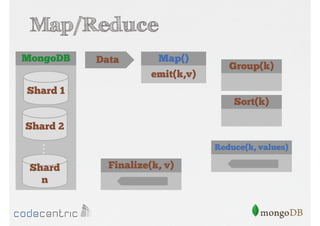
Das Dokument bietet eine umfassende Einführung in MongoDB für Java-Programmierer, einschließlich der Grundlagen der NoSQL-Datenbank, ihrer Architektur sowie der Datenmanipulation und Abfrage. Es werden wichtige Konzepte wie ACID vs. BASE, horizontale und vertikale Skalierung, Aggregationsframework sowie die Verwendung von MapReduce behandelt. Zudem werden praktische Beispiele zur Datenbankerstellung, -abfrage und -aktualisierung gegeben, um die Flexibilität und Leistungsfähigkeit von MongoDB hervorzuheben.
















































































