


![Was bedeutet Big Data?
Wikipedia: „Big Data [...] bezeichnet Datenmengen, die zu groß oder zu komplex sind oder sich zu schnell
ändern, um sie mit händischen und klassischen Methoden der Datenverarbeitung auszuwerten. “
- Große Datenmengen speichern/verarbeiten: Terrabyte
- Schnelle Antwortzeiten
- Flexible Skalierung
- Fault tolerance
- Vorausplanen der benötigten Ressourcen](https://image.slidesharecdn.com/bigdata-150428185121-conversion-gate01/85/Big-Data-Bullshit-Bingo-3-320.jpg)










![Key-Value Datenbanken
Beispiel 1:
- GET <Eventid>
- GET besucher = 100.000
- GET <Eventid><Datum>
- GET besucher:28-04-2015 = 1.000
- GET <Eventid><Datum><Stunde>
- GET besucher:28-04-2015-18-00 = 50
Beispiel 2:
- GET <Person><Datenfeld>
- GET P1:Vorname = Max
- GET P1:Nachname = Mustermann
- GET P1:Tel = [0151-1234567, 0201-987654]](https://image.slidesharecdn.com/bigdata-150428185121-conversion-gate01/85/Big-Data-Bullshit-Bingo-19-320.jpg)



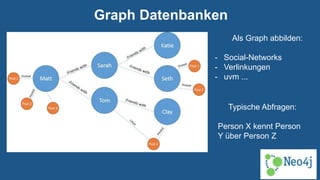




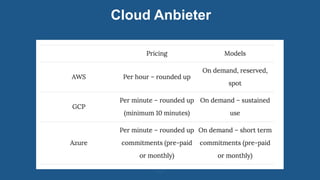
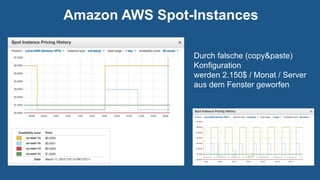






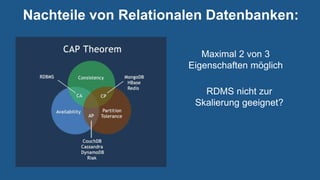
Das Dokument bietet einen technischen Überblick über Big Data, definiert es als große und komplexe Datensätze, die spezielle Verarbeitung erfordern und beschreibt wichtige Technologien wie Hadoop und NoSQL-Datenbanken. Es werden Anwendungen und Frameworks vorgestellt, inklusive realer Anwendungsfälle sowie die Vorteile von Cloud-Diensten im Bereich Big Data. Zudem gibt das Dokument Einblicke in verschiedene Datenbanktypen und deren spezielle Merkmalen.












































