65-mal heruntergeladen





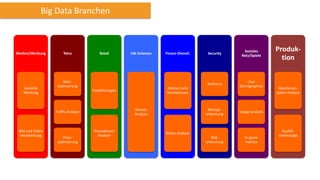


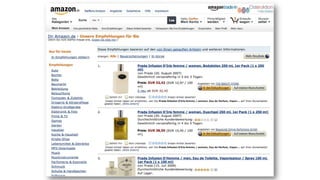
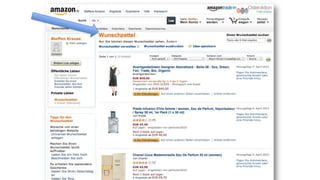









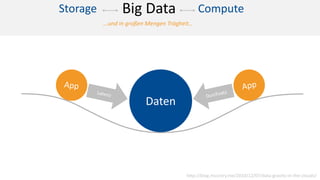
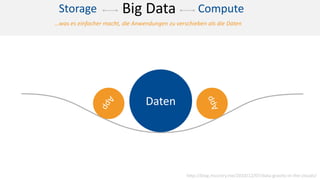

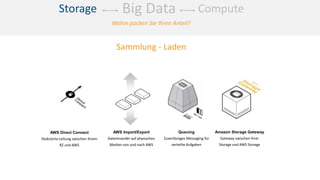


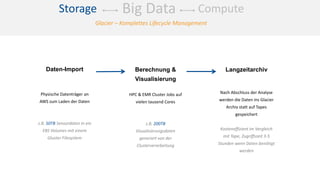
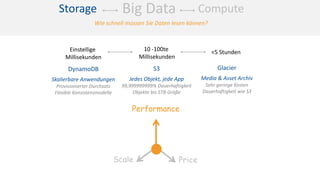

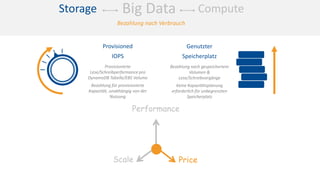
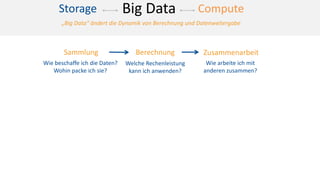
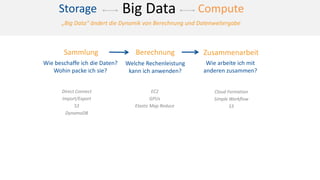





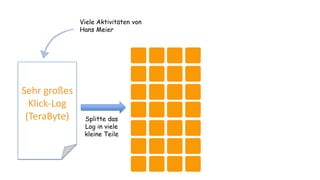
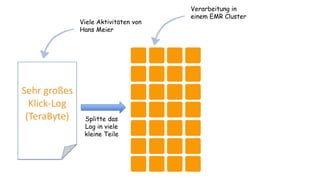
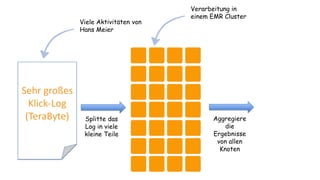
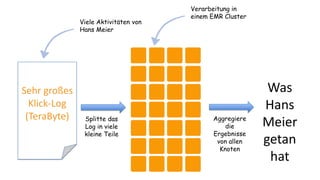
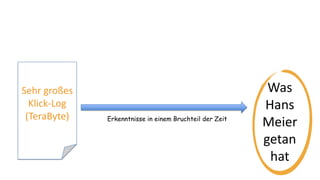

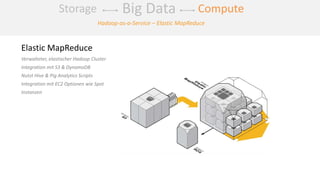
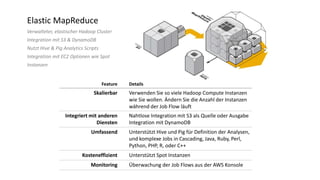




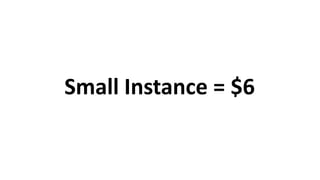

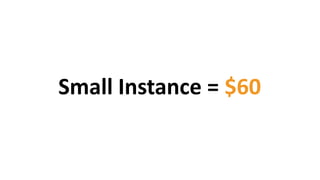


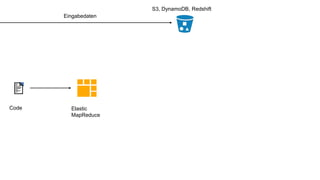
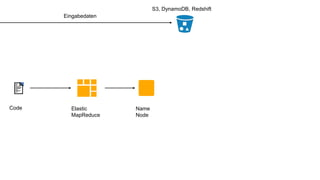
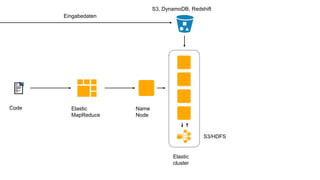
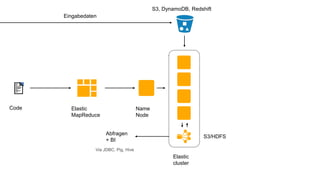
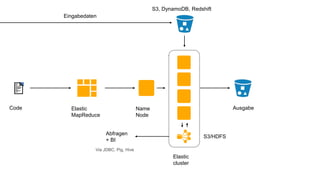

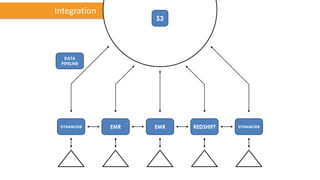



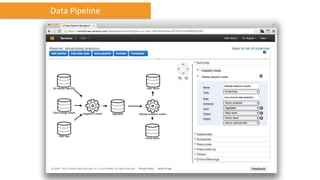
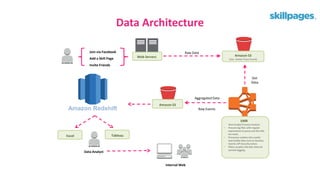

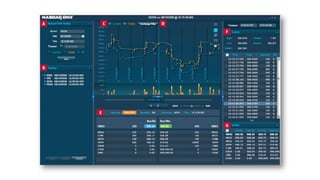
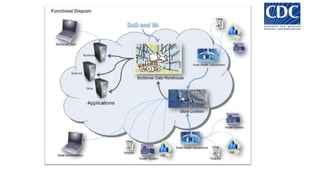

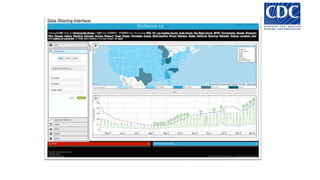






Das Dokument behandelt das Thema Big Data und dessen Nutzung zur Generierung von Wettbewerbsvorteilen durch die Analyse großer Datenmengen in verschiedenen Branchen. Es erläutert verschiedene Dienstleistungen und Technologien von AWS, die zur Sammlung, Speicherung, Analyse und Verbreitung von Daten eingesetzt werden können. Zudem werden die Vorteile einer Cloud-basierten Infrastruktur für Big Data-Operationen hervorgehoben, einschließlich Kosteneffizienz und Skalierbarkeit.























































































