Als PDF, PPTX herunterladen
![Wilfried Hoge
Leading Technical Sales Professional
Senior IT Architect Information Management
IBM Deutschland
Big Value from Big Data
Fertig werden mit den 3 wichtigsten
Herausforderungen: Volume, Velocity und
Variety [=V3]
Seite : 1](https://image.slidesharecdn.com/ibm-bigvaluefrombigdata-111201035231-phpapp01/85/IBM-Big-Value-from-Big-Data-1-320.jpg)
![Wilfried Hoge
Leading Technical Sales Professional
Senior IT Architect Information Management
IBM Deutschland
Big Value from Big Data
Fertig werden mit den 3 wichtigsten
Herausforderungen: Volume, Velocity und
Variety [=V3]
Seite : 1](https://image.slidesharecdn.com/ibm-bigvaluefrombigdata-111201035231-phpapp01/75/IBM-Big-Value-from-Big-Data-1-2048.jpg)


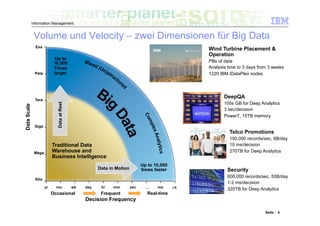
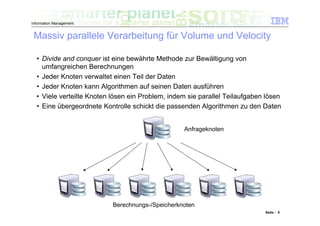


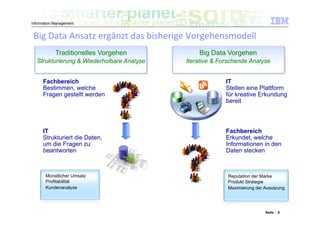

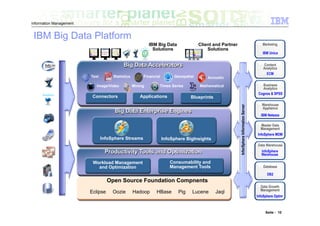

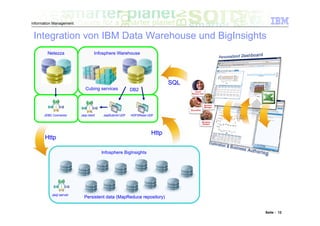
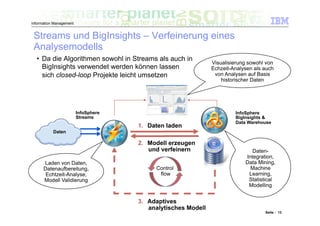
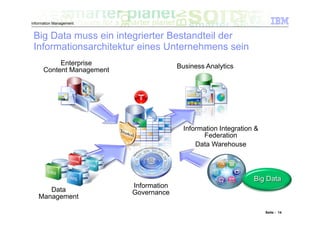
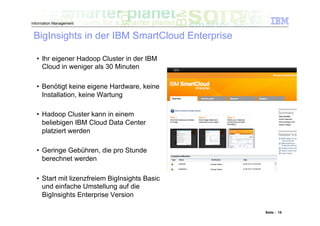

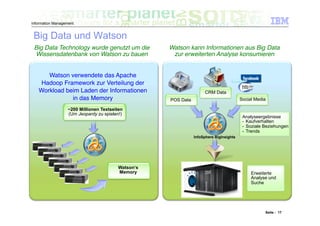



Das Dokument befasst sich mit den Herausforderungen und Technologien im Bereich Big Data, insbesondere den drei Dimensionen Volume, Velocity und Variety. Es wird erörtert, wie Unternehmen durch effiziente Datenanalyse strategische Vorteile aus den ständig wachsenden und vielfältigen Datenmengen ziehen können. Zudem werden Technologien wie IBM Netezza und BigInsights vorgestellt, die eine effektive Verarbeitung und Analyse von Big Data ermöglichen.








































































