Downloaden Sie, um offline zu lesen

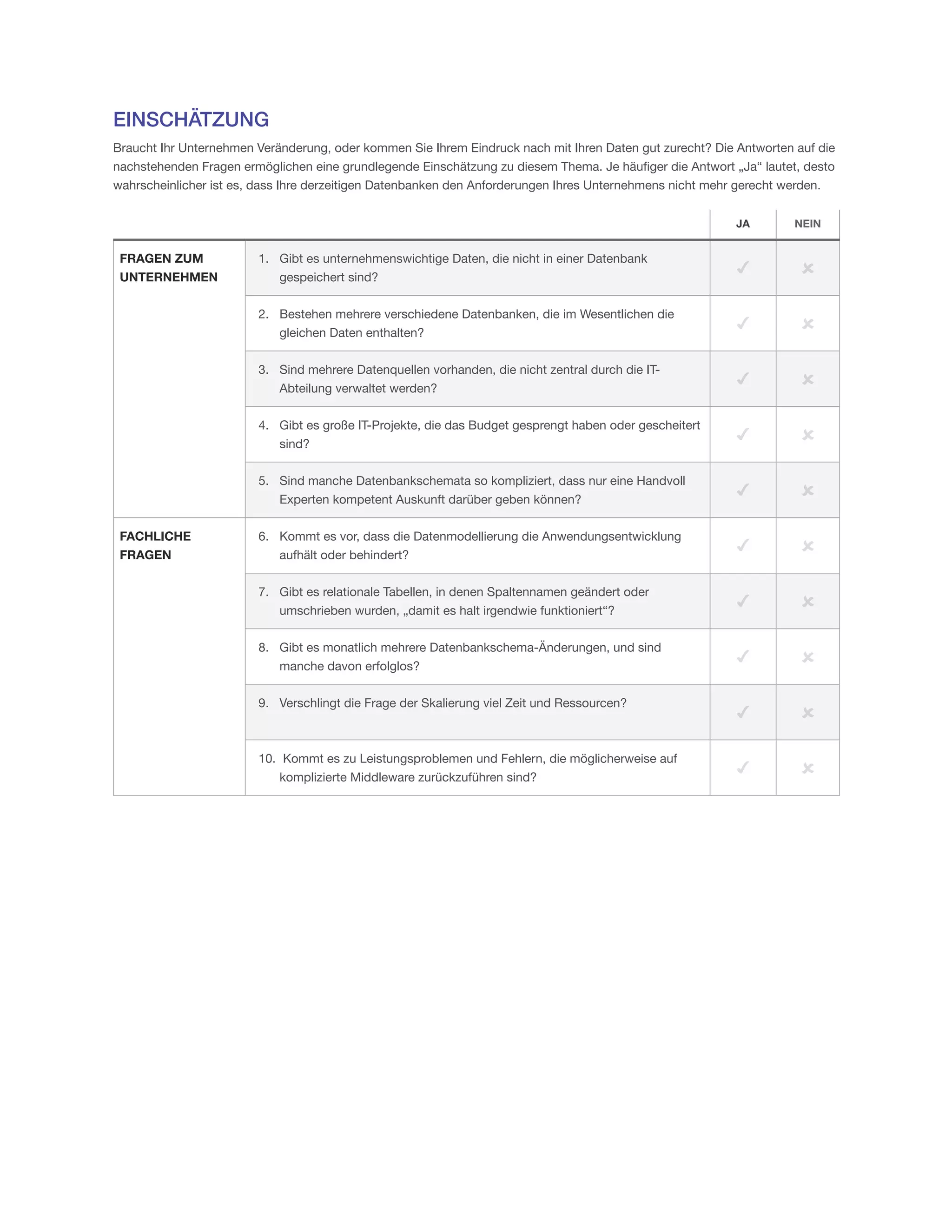














Das MarkLogic-Whitepaper beschreibt die Herausforderungen, vor denen Unternehmen bei der Verwaltung riesiger, heterogener Datenmengen stehen, insbesondere unter Verwendung traditioneller relationaler Datenbanken, die nicht für die heutigen Anforderungen ausgelegt sind. Es wird betont, dass Unternehmen durch den Übergang zu neuen Datenbankmodellen wie MarkLogic ihre Daten effektiver nutzen und Innovationen vorantreiben können. In einem Umfeld von 'Big Data' sind Flexibilität, Geschwindigkeit und Vielfalt der Daten entscheidend, um konkurrenzfähig zu bleiben.



























