30-mal heruntergeladen



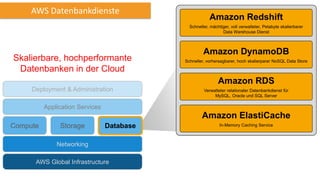
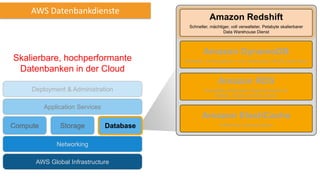


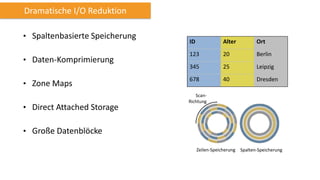


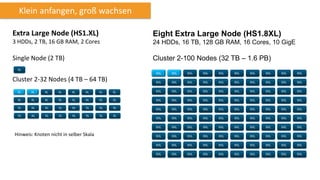








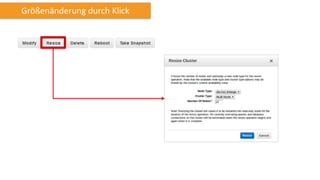

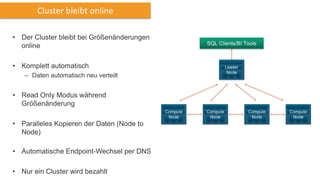














Amazon Redshift ist ein vollständig verwalteter, schneller und kostengünstiger Datenlagerdienst, der eine hohe Flexibilität und Abrechnung nach Nutzung bietet. Es unterstützt paralleles Laden von Daten und bietet eine Architektur mit Leader- und Compute-Knoten zur Optimierung von Abfragen und Datenmanagement. Redshift ist kompatibel mit bestehenden ETL- und BI-Tools und bietet umfassende Sicherheits- und Verfügbarkeitslösungen, einschließlich kontinuierlicher Backups auf Amazon S3.









































































