Downloaden Sie, um offline zu lesen









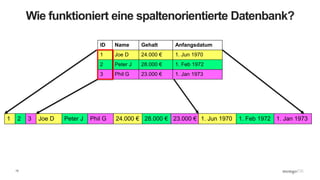



![17
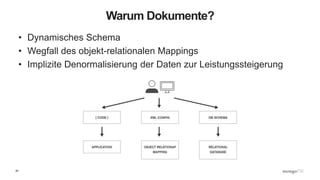
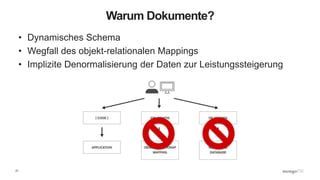
Dokumentenorientierte Datenbanken
• Keine PDF-, Word- oder HTML-Dokumente
• Dokumente sind verschachtelte Strukturen, die mit Javascript Object Notation (JSON) erstellt
werden
{
name : “Benjamin Lorenz”,
title : “Senior Solutions Architect”,
Address : {
address : “An der Welle 4”,
city : “Frankfurt”,
zip_code : “60322”,
}
expertise: [ “MongoDB”, “Python”, “Javascript” ],
employee_number : 521,
location : [ 53.34, -6.26 ]
}](https://image.slidesharecdn.com/b2b-webinar-1-introductiontonosql-german-bl-160531141450/85/Das-Back-to-Basics-Webinar-1-Einfuhrung-in-NoSQL-17-320.jpg)
![18
Mit MongoDB werden Dokumente typisiert
{
name : “Benjamin Lorenz”,
title : “Senior Solutions Architect”,
Address : {
address : “An der Welle 4”,
city : “Frankfurt”,
zip_code : “60322”,
}
expertise: [ “MongoDB”, “Python”, “Javascript” ],
employee_number : 521,
location : [ 53.34, -6.26 ]
}
Strings
Verschachteltes Dokument
Array
Integer
Geokoordinaten](https://image.slidesharecdn.com/b2b-webinar-1-introductiontonosql-german-bl-160531141450/85/Das-Back-to-Basics-Webinar-1-Einfuhrung-in-NoSQL-18-320.jpg)


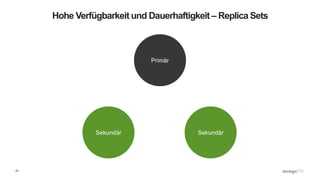
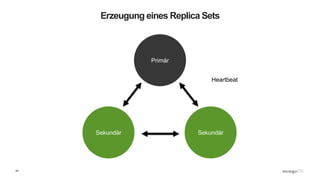
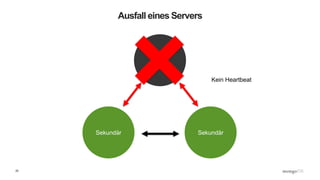
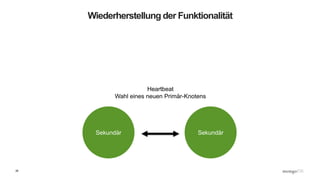
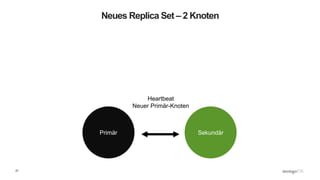
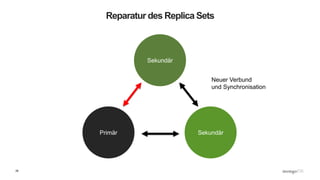
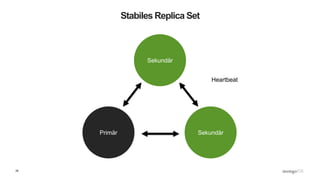
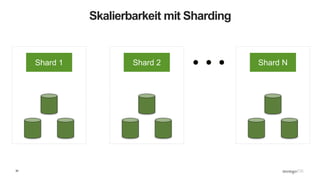

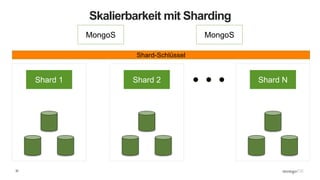






Das Webinar 'Back to Basics 2016' bietet eine Einführung in NoSQL-Datenbanken mit einem speziellen Fokus auf MongoDB und behandelt Themen wie die verschiedenen Typen von NoSQL-Datenbanken, ihre Skalierbarkeit, Leistungsfähigkeit und essentielle Funktionen wie Replica Sets und Sharding. Es werden die Vorteile von dokumentenorientierten Datenbanken hervorgehoben, einschließlich dynamischer Schemata und effizienter Datenverarbeitung. Weitere Webinare sind geplant, um praktische Anwendung und Entwicklung in MongoDB zu vermitteln.













































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











