57-mal heruntergeladen







![• Quelle: Amazon (Oktober 2007)
• Problem: Notwendigkeit für ~100% Verfügbarkeit
• Lösung:
• Partitionierung der Daten auf 1-n gleichwertige Nodes (masterless)
• Gleichmäßige Verteilung via Consistent Hashing
• Hohe Verfügbarkeit mittels n * Replikation der Daten
• Intra-Cluster Kommunikations Protokoll (Gossip)
12
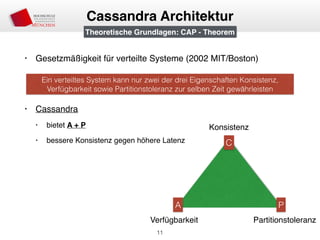
Cassandra Architektur
“[…] even if disks are failing, network routes are flapping, or data centers are
being destroyed by tornados […]”
Theoretische Grundlagen: Dynamo Paper](https://image.slidesharecdn.com/apachecassandra-150131034345-conversion-gate01/85/Apache-Cassandra-Einfuhrung-12-320.jpg)


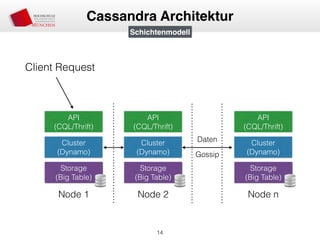
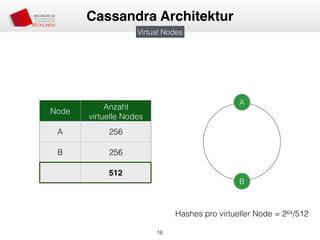
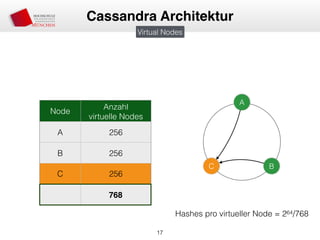
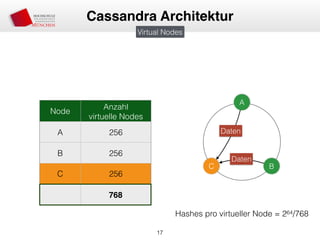
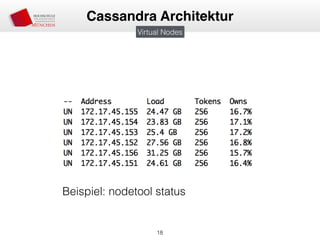
![• Partitioner entscheiden über Platzierung auf Node
• Murmur3Partitioner (MurmurHash), RandomPartitioner (MD5)
• Murmur3 Bereich: [-263, 263-1]
• Aufteilung des Bereichs in virtuelle Nodes
• Zuordnung von virtuellen Nodes zu “echten” Nodes
• Node 1 —> n virtueller Node
• Verschiedene Anzahl von virtuellen Nodes möglich (Lastenverteilung)
• Erweiterung des Clusters = Minimale Daten-Neuverteilung
15
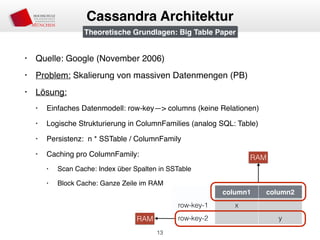
Cassandra Architektur
Consistent Hashing und Virtual Nodes](https://image.slidesharecdn.com/apachecassandra-150131034345-conversion-gate01/85/Apache-Cassandra-Einfuhrung-17-320.jpg)


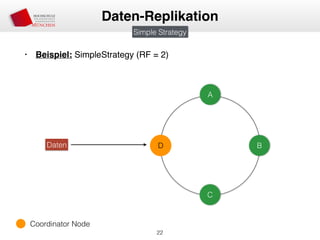
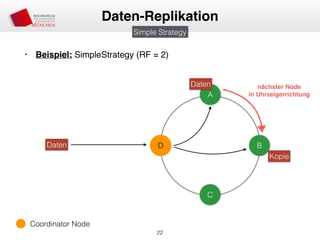
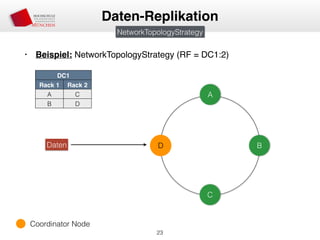
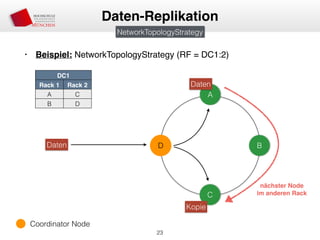
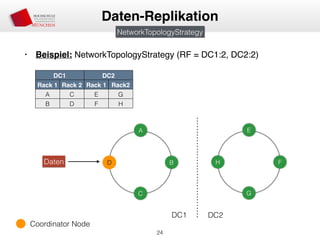
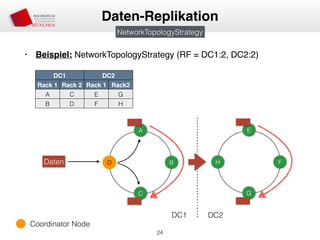
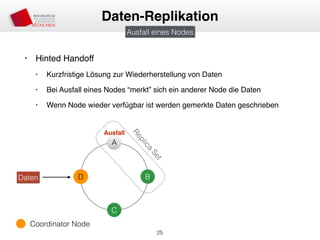
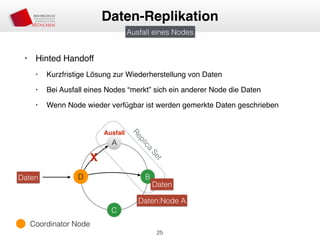
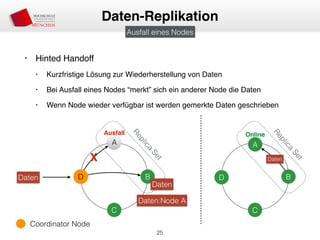



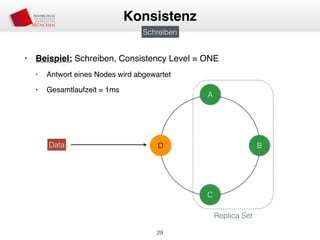
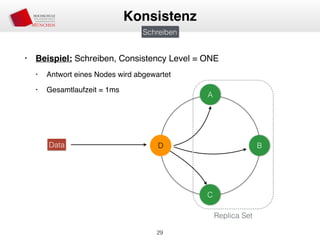
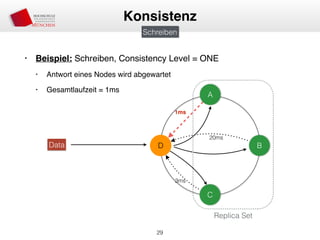
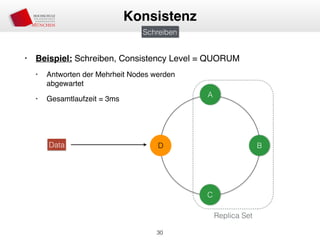
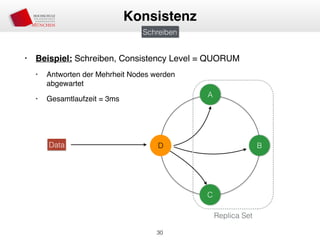
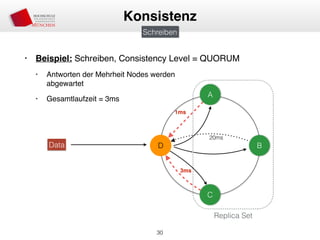
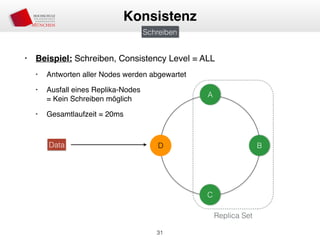
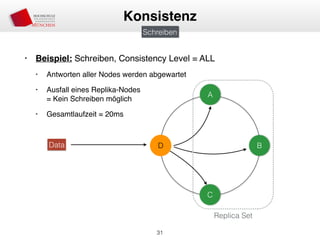
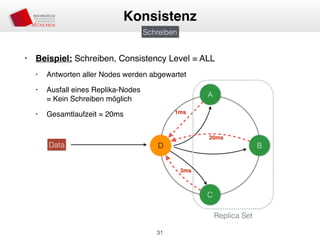
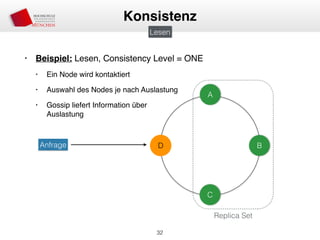
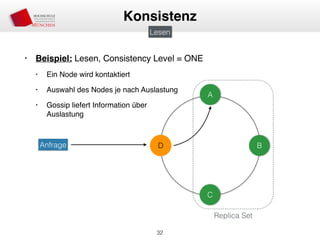
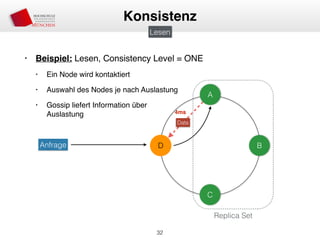
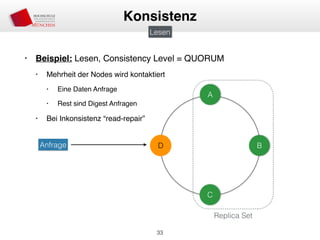
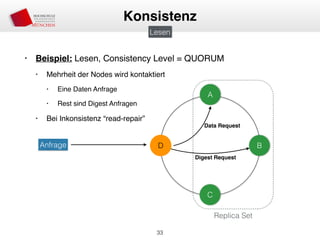
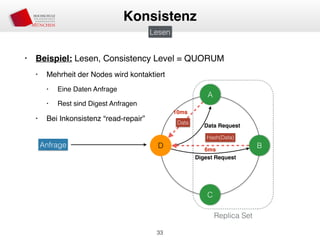
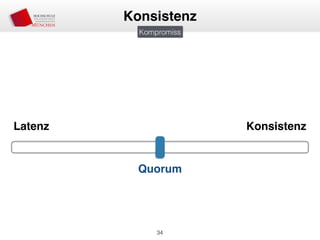




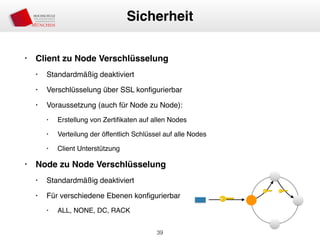




Das Dokument behandelt die Architektur und Leistungsmerkmale von Apache Cassandra, einem verteilten NoSQL-Datenbanksystem, das seit 2008 als Open Source verfügbar ist. Es werden Aspekte wie Daten-Replikation, Konsistenz, Sicherheit sowie die Skalierbarkeit des Systems in produktiven Umgebungen erläutert, insbesondere im Finanzsektor. Zudem werden verschiedene Strategien und technische Grundlagen wie das CAP-Theorem sowie Authentifizierungs- und Autorisierungsmechanismen besprochen.














































