32-mal heruntergeladen










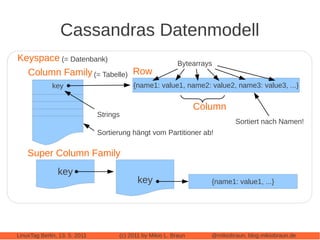
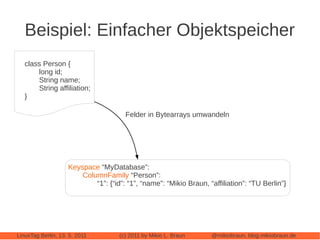


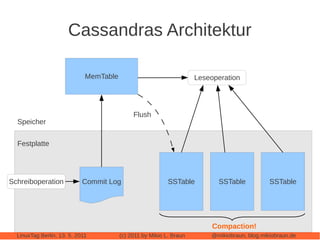

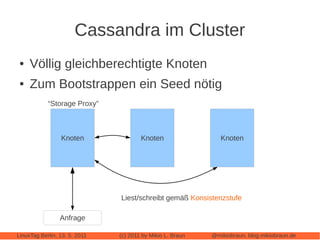






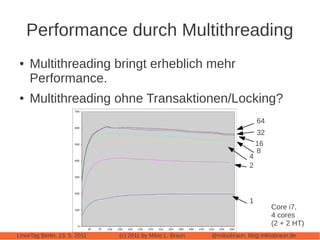


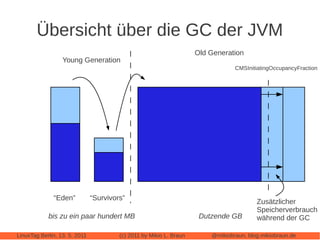
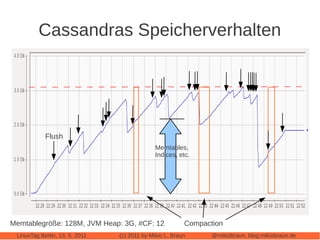

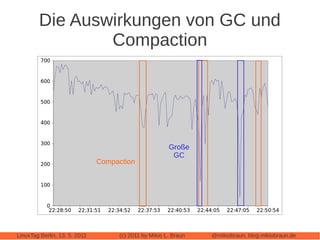





Das Dokument bietet eine umfassende Einführung in Apache Cassandra, eine NoSQL-Datenbank, die für webbasierte Anwendungen konzipiert ist und sich von klassischen relationalen Datenbanken unterscheidet. Es beleuchtet zentrale Eigenschaften wie die 'eventually consistent'-Strategie, die Peer-to-Peer-Architektur und das Cluster-Management sowie deren Anwendungen und Varianten. Der Autor diskutiert auch praktische Erfahrungen, Leistungstuning und vergleicht Cassandra mit anderen NoSQL-Alternativen.








































