Als PDF, PPTX herunterladen

















![LACP
IEEE 802.3ad != IEEE 802.3ad
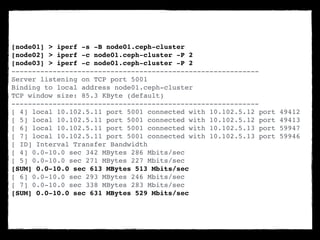
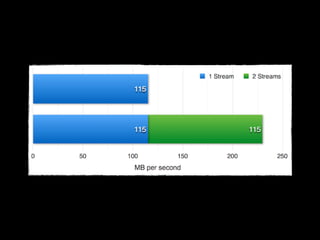
[node01] > iperf -s -B node01.ceph-cluster!
[node02] > iperf -c node01.ceph-cluster -P 2!
[node03] > iperf -c node01.ceph-cluster -P 2!
------------------------------------------------------------!
Server listening on TCP port 5001!
Binding to local address node01.ceph-cluster!
TCP window size: 85.3 KByte (default)!
------------------------------------------------------------!
[ 4] local 10.102.5.11 port 5001 connected with 10.102.5.12 port 49412!
[ 5] local 10.102.5.11 port 5001 connected with 10.102.5.12 port 49413!
[ 6] local 10.102.5.11 port 5001 connected with 10.102.5.13 port 59947!
[ 7] local 10.102.5.11 port 5001 connected with 10.102.5.13 port 59946!
[ ID] Interval Transfer Bandwidth!
[ 4] 0.0-10.0 sec 342 MBytes 286 Mbits/sec!
[ 5] 0.0-10.0 sec 271 MBytes 227 Mbits/sec!
[SUM] 0.0-10.0 sec 613 MBytes 513 Mbits/sec!
[ 6] 0.0-10.0 sec 293 MBytes 246 Mbits/sec!
[ 7] 0.0-10.0 sec 338 MBytes 283 Mbits/sec!
[SUM] 0.0-10.0 sec 631 MBytes 529 Mbits/sec](https://image.slidesharecdn.com/privatecloudmitopensource-140823052105-phpapp02/85/Private-Cloud-mit-Open-Source-20-320.jpg)


























![Handout bei CenterDevice
3
Der Weg in die private Cloud ist steinig. Be-
geben Sie sich auf ihn, stehen Sie vor zahl-
losen Entscheidungen und der Auswahl aus
einer Vielzahl von Technologien. Dazu ge-
hören insbesondere die zur Virtualisierung
der Speicher- und Rechenkapazitäten.
Wir setzen hierbei für die codecentric AG auf
den Storage Cluster Ceph und die Virtuali-
sierungsplattform OpenStack, mit denen wir
eine private Cloud für die Firma CenterDevice
erfolgreich umgesetzt haben.
Ceph und OpenStack sind mächtige Plattfor-
men, die sich hervorragend ergänzen und au-
ßergewöhnliche Leistung bieten. Aus diesem
Grund werden sie von vielen Firmen produk-
tiv eingesetzt. In diesem Sonderheft der code-
centric AG beschreiben wir die Grundlagen
dieser Technologien in den beiden folgenden
Artikeln „Grundlagen und technische Konzep-
te des Ceph-Storage-Clusters” und „Mit Open-
Stack eine eigene Cloud aufbauen”, die zuerst
in den Ausgaben 7.2014 und 8.2014 im Java-
Magazin erschienen sind.
Viel Spaß beim Lesen. Für alle Fragen, die of-
fen bleiben, sind wir für Sie da.
Dr. Lukas Pustina und Daniel Schneller
5
Dr. Lukas Pustina hat langjähri-
ge Erfahrung in der Entwicklung
und dem Betrieb von verteilten
Systemen. Er hat dabei stets ein
Auge auf neue Technologien in
diesem Umfeld. Zur Zeit arbei-
tet er als Leiter des Bereichs Inf-
rastruktur bei der CenterDevice
GmbH an der Realisierung einer
hochskalierbaren Cloudsoftware.
lukas.pustina@codecentric.de
@drivebytesting
Daniel Schneller beschäftigt
sich seit über 15 Jahren mit
dem Entwurf und der Umset-
zung komplexer Software- und
Datenbanksysteme und ist un-
ter anderem Autor des MySQL
Admin Cookbook. Er leitet der-
zeit er bei der CenterDevice
GmbH den Bereich Mobile De-
velopment.
daniel.schneller@codecentric.de
@dschneller
Grundlagen und technische Konzepte des Ceph-Storage-Clusters
Ceph ist ein Storage-Cluster, der auf handelsüblicher Serverhardware läuft und problemlos Speicher-
mengen von wenigen hundert Gigabyte bis hin zu Peta- oder gar Exabytegröße bereitstellen kann. Dabei
sorgt eine intelligente Peer-to-Peer- Kommunikation dafür, dass alle abgelegten Daten redundant und
hochverfügbar gespeichert werden.
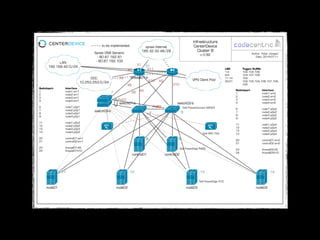
Dieser Artikel beleuchtet die grundlegenden Konzepte von Ceph am Beispiel unserer Installation.
Diese stellt derzeit insgesamt 175 TB Speicherplatz – verteilt über 48 Festplatten in vier Servern –
als hochperformanter Object Store und verteiltes Dateisystem zur Verfügung.
Abgrenzung zu SANs
Wenn schnelle Speicherkapazität in großer
Menge benötigt wird, richten sich die Blicke
traditionell in Richtung Storage Area Networks
(SAN). Diese oft via Fibre Channel angebun-
denen Speichernetzwerke bieten den ange-
schlossenen Rechnern virtuelle Block-Devices
zum Beispiel über das iSCSI-Protokoll an. Im
Hintergrund sorgen sie für eine automatische
Verteilung der Daten auf eine Anzahl indivi-
dueller Festplatten. SANs sind weit verbrei-
tet, haben aber einige Nachteile. Neben dem
Komponenten begibt man sich in ein Abhän-
gigkeitsverhältnis vom jeweiligen Hersteller,
da trotz Bestrebungen in dieser Richtung eine
Interoperabilität zwischen Systemen verschie-
dener Anbieter nicht gewährleistet ist.
Soll ein SAN hochverfügbar ausgelegt werden,
bedeutet dies normalerweise eine Verdopp-
lung der Hardware, einhergehend mit den
entsprechenden Kosten. Eine nachträgliche
Aufrüstung ist nur im Rahmen dessen mög-
lich, was der Hersteller des Systems dafür an
kompatiblen Optionen vorsieht.
Im Gegensatz dazu basiert Ceph vollständig
auf handelsüblicher Serverhardware mit da-
zugehörigen einfachen, zum Beispiel via SAS
verbundenen, Speichermedien. Diese können
-
geschlossen werden.
Die Kommunikation zwischen den Komponen-
ten erfolgt über 1-GBit- oder 10-GBit-Ethernet
und kommt ohne zentrale Komponenten –
wie zum Beispiel SAN-Controller – aus. Damit
gibt es keinen Single Point of Failure. Die ein-
zelnen Knoten tauschen sich untereinander
über Peer-to-Peer-Kommunikation aus, um
abgelegte Daten zuverlässig und schnell abzu-
legen bzw. darauf zugreifen zu können.
RADOS
Kernbestandteil von Ceph ist RADOS, das Re-
liable A tonomic Distributed Object Storage.
Hierbei handelt es sich um einen verteilten
Object Store, der die Intelligenz aller beteilig-
ten Knoten nutzt, um die Notwendigkeit einer
zentralen Verwaltungsinstanz zu vermeiden.
RADOS skaliert durch die horizontale Vertei-
lung aller anfallenden Aufgaben nahezu be-
6 7
liebig und trägt dabei Sorge dafür, dass ge-
speicherte Daten dynamisch verteilt und bei
-
nisiert werden, gleichzeitig aber jederzeit zu-
greifbar sind.
Ein Objekt im Sinne von RADOS ist eine beliebi-
ge Menge von Daten, die unter einem eindeuti-
gen Schlüssel abgelegt werden. Dabei spielt die
Größe dieser Objekte keine wesentliche Rolle.
Es kann sich dabei um einen nur wenige Bytes
langen Text handeln oder um ein hunderte Gi-
gabyte großes Disk Image.
Object Storage Devices
Ungeachtet aller logischen Strukturen müs-
sen auch in Ceph letztlich Daten auf physi-
schen Speichermedien abgelegt werden. In
der Ceph-Terminologie handelt es sich hier-
bei um so genannte Object Storage Devices
(OSDs). Im Normalfall sind dies Festplatten.
Es kann sich jedoch auch – insbesondere zu
Testzwecken – um Loopback Devices oder
einzelne Verzeichnisse in einem existierenden
Dateisystem handeln. Für den Produktions-
einsatz werden in jedem Fall dedizierte Plat-
ten empfohlen.
Jede Platte wird im Rahmen der Installation
von Ceph mit dem XFS-Dateisystem forma-
tiert. In unserem Cluster ergeben sich dadurch
48 OSDs mit je ca. 3,7 TB formatierter Kapazi-
tät; insgesamt also etwa 175 TB Speicherplatz.
Zu beachten ist, dass Struktur und Inhalt der
in diesen Dateisystemen gespeicherten Da-
ten vollständig Ceph obliegen. Jeder manuelle
-
fährden und sollte daher dringend unterlas-
sen werden.
Für jedes OSD wird auf dem jeweiligen Ser-
ver ein einzelner Ceph-OSD-Daemon-Prozess
gestartet. Dieser ist verantwortlich dafür, das
Gerät zu überwachen und den von ihm bereit-
gestellten Platz für den Cluster verfügbar zu
machen.
Die Aufgaben, die der OSD Daemon dabei
übernimmt, sind vielfältig. Er erledigt unter
anderem die Überwachung der Verfügbarkeit
des von ihm betreuten OSD, das Manage-
ment der Netzwerkkommunikation mit Ceph-
Clients und anderen OSD Daemons. Darüber
hinaus führt er regelmäßige Integritätschecks
(„Scrubbing“) der gespeicherten Daten durch,
um Datenkorruption durch Bit-Fehler oder an-
zu korrigieren. Darüber hinaus sind OSDs
Objektredundanz verantwortlich.
An dieser Stelle sei deshalb erwähnt, dass ex-
plizit davon abgeraten wird, Ceph auf RAID Vo-
lumes oder anderen bereits auf andere Weise
virtualisierten Datenträgern aufzusetzen. Zen-
trale Aufgabe der OSD Daemons ist es, je ein
konkretes Stück Storage-Hardware zu verwal-
Datensicherheit, im Cluster bereitzustellen.
Dies ist jedoch nur dann möglich, wenn sie
Medium haben und es in Eigenregie steuern
können. Andernfalls käme es zu Wechselwir-
kungen der verschiedenen Abstraktionsebe-
nen, die in Summe negative Auswirkungen
Performance hätten.
Skalierbarkeit
Cephs theoretisch unbegrenzte Skalierbarkeit
und Flexibilität basiert auf einer breiten Ver-
teilung aller anfallenden Aufgaben auf mög-
lichst viele Maschinen. Ab einer bestimmten
Clustergröße wäre selbst ein sehr leistungs-
starker zentraler Objektbroker mit der Last
-
len Lookup Table und anderer Verwaltungs-
aufgaben entstünde.
Neben der reinen Lastverteilung bewirkt die
Verwendung intelligenter Knoten weiterhin,
dass Ceph den Ausfall von Teilen der Infra-
struktur verkraften kann, ohne dass dadurch
notwendigerweise der gesamte Cluster beein-
trächtigt würde.
Eine Konsequenz dieses Verzichts auf eine
zentrale Verwaltungsinstanz ist jedoch, dass
Clients keine dedizierte Anlaufstelle haben, an
die sie Anfragen und Aufgaben richten könn-
ten. Ceph-Clients sind daher selbst mit einer
Konkret verwenden sie den gleichen CRUSH-
Algorithmus wie die OSD Daemons, um be-
rechnen zu können, wo im Cluster sich die
erreichen sind.
CRUSH-Algorithmus
Die Bestimmung des Ablageorts eines Objekts
in Ceph erfolgt vollständig über den so ge-
nannten CRUSH-Algorithmus [1] in praktisch
konstanter Zeit. Der Algorithmus ermittelt
dabei – ähnlich einer Hash-Funktion – basie-
rend auf einigen Eingabeparametern die tat-
sächlichen Ablageorte zu speichernder bzw.
zu lesender Objekte. Dabei wird angestrebt,
die Ressourcen im Cluster möglichst sinnvoll
auszulasten. In die Berechnung gehen neben
dem Objektnamen auch ein wählbarer Redun-
danzlevel und eine clusterweite Gesamtzahl
von Placement Groups ein. Eine Placement
Group (PG) ist eine logische Gruppierung von
Objekten, die jeweils auf dem gleichen Satz
von physikalischen Geräten gespeichert wer-
den (Abb. 1).
Die Gesamtanzahl an Placement Groups wird
beim ersten Aufsetzen des Clusters initial fest-
gelegt, kann aber bei Bedarf, insbesondere bei
-
träglich angepasst werden. Ein typischer Wert
liegt bei etwa 100 PGs pro OSD.
Diese Vorgehensweise ermöglicht es Ceph-Cli-
ents, selbstständig zu bestimmen, welcher OSD
Daemon für die Speicherung eines Objekts zu-
ständig ist und direkt mit diesem zu kommuni-
zieren, anstatt hierfür einen dedizierten Dienst
als Mittelsmann bemühen zu müssen.
Eine besondere Rolle kommt dem jeweils ers-
ten OSD zu, der für ein Objekt errechnet wird.
Er ist dafür verantwortlich, die vom Client er-
haltenen Daten entsprechend des gewünsch-
ten Grads an Redundanz an weitere OSDs zu
übermitteln. Erst wenn alle Erfolg gemeldet
haben, gilt eine Schreiboperation aus Sicht des
Clients als abgeschlossen. Abbildung 2 zeigt,
wie ein Objekt mit dreifacher Redundanz ge-
speichert wird.
8 9
Stabile Zuordnungen
CRUSH ist darauf ausgelegt – an dieser Stelle
im Unterschied zu klassischen Hash-Funktio-
nen – auch bei Veränderung der Eingabepara-
meter möglichst stabile Ergebnisse zu liefern.
Ändert sich die Anzahl verfügbarer OSDs, zum
Beispiel durch Ausfall einer Festplatte oder
Hinzufügen weiterer zur Erhöhung der Kapa-
zität, werden gerade so viele Daten wie nötig
umverteilt, um wieder eine gleichmäßige Aus-
lastung zu erzielen.
Der überwiegende Teil der Daten bleibt an Ort
und Stelle (Abb. 3). Im Gegensatz dazu hätte
die Verwendung einer echten Hash-Funktion
die Umverteilung aller bestehenden Daten
zur Folge. Da Ausfälle und Erweiterungen ab
einer gewissen Cluster-Dimension alltägliche
Vorgänge sind, wäre ein solches System bald
nahezu ausschließlich mit Rebalancierung be-
schäftigt.
Als zusätzlichen Faktor kann Ceph jeden OSD
basierend auf seiner Kapazität und Leistung
unterschiedlich gewichten, um insgesamt
Abbildung 3 -
eine möglichst ideale Ausnutzung aller Res-
sourcen zu gewährleisten. Hat etwa ein spä-
ter zum Cluster hinzugefügter Server deutlich
leistungsstärkere Hardware, wie zum Beispiel
eine oder mehrere SSDs, die als dediziertes
Medium für das Schreiben von Journaleinträ-
-
sichtigen und dieser Maschine mehr Arbeit
zuweisen als anderen, schwächeren Knoten.
Monitore
Wer bis hierhin gelesen hat, stellt sich inzwi-
schen vielleicht zu Recht die Frage, wie die
Beteiligten eines Ceph-Systems, Server wie
Clients, Informationen über die aktuelle Kon-
-
besondere wäre es kaum praktikabel, allen
-
datei mit allen relevanten Clusterparametern
bereitzustellen. Stattdessen sieht die Ceph-
Architektur hierfür einen dedizierten Dienst
vor: den Ceph-Monitor. In jedem Ceph-Clus-
ter existiert wenigstens ein Ceph-Monitor.
Ceph-Monitore haben die Aufgabe, eine stets
aktuelle Cluster-Map bereitzustellen. Dabei
handelt es sich um eine aus mehreren Einzel-
Maps zusammengesetzte Gesamtbeschrei-
bung des Clusterzustands. Ein Client, der sich
mit einem Monitor verbindet, kann dadurch
alle relevanten Systeminformationen erfah-
ren. Dazu gehören unter anderem Status und
Adressen aller OSD Daemons, weiterer Moni-
tore und Metadata-Server (mehr dazu später).
Bevor ein Ceph-Client also Daten mit einem
oder mehreren OSD Daemons austauschen
kann, muss er zunächst Kontakt zu einem
Ceph-Monitor aufnehmen, um eine aktuelle
Cluster-Map abzurufen. Mittels dieser Map
und durch Anwendung des CRUSH-Algorith-
mus lässt sich die Position aller Objekte – und
damit auch, von welchen OSD Daemons sie
erreichbar sind – errechnen. An dieser Stelle
endet damit die Abhängigkeit des Clients vom
dann unabhängig über direkte Kommunikati-
on mit den zuständigen OSD Daemons.
Im Sinne der Ausfallsicherheit und Skalier-
barkeit sollten Cluster sinnvollerweise immer
mehr als einen einzigen Monitor haben. An-
dernfalls führte dies den zuvor genannten
Vorteil eines Verzichts auf zentrale Kompo-
nenten ad absurdum, da ein einzelner Moni-
tor ein Single Point of Failure für das Gesamt-
system würde.
Ceph-Monitore synchronisieren sich unterein-
ander und verwenden mit Paxos [3] einen Al-
gorithmus zur verteilten Entscheidungs- und
einzelner Monitore weiterhin eine korrekte
Cluster-Map zur Verfügung gestellt werden
kann, solange noch eine Mindestanzahl von
Monitoren erreichbar ist.
-
rationsdatei, die einen oder mehrere Monito-
re mit ihren Adressen im Netzwerk benennt.
Die Ceph-Monitore selbst verwenden einen
Teil der Cluster-Map (die Monitor-Map), um
jederzeit ein über das Cluster hinweg konsis-
tentes Wissen über die verfügbaren Monito-
re zu haben. Bei der Installation eines neuen
Clusters wird die initiale Monitor-Map mittels
entsprechender Tools basierend auf einer
keine weitere Relevanz mehr hat.
Selbst für kleine Cluster sollten mindestens
drei Monitore aufgesetzt werden, um auch bei
Ausfall eines einzelnen weiterhin mehrheits-
fähig zu bleiben. Wächst der Cluster, können
nach Bedarf weitere hinzugefügt werden. Im
Idealfall werden Monitore auf dedizierten Ser-
vern betrieben, können aber auch auf beste-
henden Maschinen laufen, die auch OSDs be-
reitstellen. In Testinstallationen, bei denen ein
OSD Daemon keine dedizierte Platte, sondern
Speicher in einem existierenden Dateisystem
verwendet, sollte allerdings zumindest ein
anderes Gerät zur Speicherung der Monitor-
fsyncs() auslösen und damit die Performance
Pools
Pools ermöglichen eine logische Strukturie-
rung der Gesamtressourcen des Clusters, die
individuell je nach Anforderung abweichend
-
den können. Wenn ein Cluster initial aufge-
setzt wird, werden alle Objekte im Standard-
pool namens „data“ abgelegt. Pools sind somit
vergleichbar mit Mount Points oder Laufwer-
ken.
Mirroring
Pro Pool können verschiedene Parameter
unabhängig von den Defaults des gesamten
10 11
interessant ist hier der Grad der Redundanz,
mit dem Objekte, die in einem bestimmten
Pool abgelegt werden, über das Cluster rep-
liziert werden. Standardeinstellung für den
„data“-Pool sowie neu angelegte weitere
Pools ist 2. Das bedeutet, dass jedes Objekt
doppelt im Cluster vorliegt. Dies wirkt – ganz
ähnlich wie ein RAID Mirror – Hardwareausfäl-
len entgegen, indem auch beim Wegfall einer
Kopie die Daten dennoch weiterhin zugreifbar
bleiben.
Basierend auf der Kritikalität der zu spei-
chernden Objekte bietet es sich daher an,
verschiedene Pools anzulegen und entspre-
erwähnten Cluster unseres Dokumentenma-
nagementprodukts CenterDevice verwenden
wir einen Pool mit dreifacher Redundanz (also
das Originalobjekt und zwei Kopien) für vom
Kunden hochgeladene Dokumente.
Neben der reinen Erhöhung der Ausfallsicher-
heit erlaubt das Vorhalten mehrerer Kopien
von Objekten auch eine Verteilung von Lese-
anfragen auf alle vorhandenen Kopien. Da-
her kann es – je nach Anwendungsfall – auch
sinnvoll sein, Objekte, die besonders hoch-
frequent gelesen werden, in einen Pool mit
höherer Redundanz zu legen, selbst wenn sie
aus anderen Gesichtspunkten keine mehrfa-
che Speicherung benötigten.
Striping
Ceph unterstützt neben dem Mirroring auch
das Striping von geschriebenen Daten. Dadurch
lässt sich der Durchsatz insbesondere beim Sch-
reiben weit über die maximale Geschwindigkeit
eines einzelnen OSD hinaus steigern.
Um Verwirrung zu vermeiden, verwenden wir
zur besseren Unterscheidung an dieser Stelle
das im Cluster gespeichert werden soll. Eine Da-
tei wird – ganz wie bei einem RAID 0 – nicht „am
Stück“ abgelegt, sondern in mehrere Einzelteile
gesplittet, die im Cluster abgelegt werden. Drei
-
gung der Daten:
die zu speichernde Datei zerlegt wird (zum
Beispiel 64 KB).
Objekten zusammengefasst (daher die
-
chert. Ein Objekt enthält dabei 1 bis n viele
Stripe Units. Daher muss die Objektgrö-
ße ein ganzzahliges Vielfaches der Stripe-
Unit-Größe sein.
einzelnen Stripe Units sequenziell in einen
Satz von Objekten, dessen Größe über die
Stripe-Anzahl geregelt wird. Nachdem eine
Stripe Unit ins letzte Objekt eines solchen
Satzes geschrieben wurde, wird die nächs-
te Unit wieder im ersten Objekt abgelegt.
Zur Verdeutlichung sei zunächst eine Stripe-
Anzahl von 1 angenommen. In diesem Fall
werden Stripe Units in ein einziges Objekt ge-
schrieben, bis dessen maximale Objektgröße
erreicht ist. Mit der nächsten Stripe Unit be-
ginnt ein neues Objekt, so lange, bis die kom-
plette Datei abgelegt wurde (Abb. 4).
Da ein einzelnes Objekt auf einem einzigen
OSD gespeichert wird, bringt dies noch keine
Verbesserung der Schreibgeschwindigkeit.
Denn die Stripe Units werden lediglich hinter-
einander in die Objekte geschrieben. Daher
erhöhen wir nun die Stripe-Anzahl auf 4.
Beim Schreiben der ersten Stripe Unit wird
nun nicht ein Objekt angelegt, sondern gleich
Abbildung 4 -
4. Die erste Stripe Unit wird in das erste Ob-
jekt geschrieben, wie im vorherigen Beispiel.
Die zweite folgt nun jedoch nicht im gleichen
Objekt, sondern wird in das nächste Objekt
des Objektsatzes gespeichert. Dies setzt sich
für die nächsten beiden Stripe Units fort. Die
fünfte Stripe Unit wird wiederum im ersten
Objekt gespeichert usw.
Genügt die kombinierte Kapazität eines kom-
plett gefüllten Objektsatzes nicht, um die Da-
tei abzulegen, wird mit der ersten Stripe Unit,
die die Kapazität übersteigt, ein neuer Objekt-
satz angelegt. Das Konzept wird deutlich in
Abbildung 5.
12 13
um einen Maximalwert handelt und kein Spei-
cherplatz für einen Objektsatz reserviert wird,
kommt es hierbei nicht zu einer Verschwen-
dung von Speicherkapazität.
Clients
Nachdem nun die Serverseite von Ceph grund-
legend beschrieben worden ist, kommen wir
zu den verschiedenen Möglichkeiten, auf Da-
ten eines Ceph-Clusters zugreifen zu können.
Swift/S3-APIs: Statt das Rad neu zu
APIs existierende Schnittstellen. Das Swift-In-
terface bietet eine weitgehend mit dem Open-
Stack-Swift-API kompatible Schnittstelle an.
Darüber hinaus existiert ein API, das weitge-
hend kompatibel mit Amazons S3 Storage Ser-
vice ist. Beide APIs lassen sich gleichzeitig über
das so genannte RADOS-Gateway verwenden.
Hierbei handelt es sich um ein FastCGI-Skript,
das die entsprechenden Endpoints bereitstellt.
Für Entwickler steht damit eine Vielzahl ferti-
ger Bibliotheken und Bindings für verschiede-
ne Sprachen und Frameworks bereit.
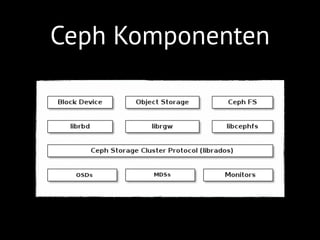
Ceph Block Device: Zur Nutzung
des Speicherplatzes im Cluster in Form von
Block Devices bringt Ceph sowohl ein Kernel-
modul als auch eine Userland Library (librbd)
mit. Über diese beiden Wege lassen sich vir-
tuelle Block Devices zur direkten Verwendung
oder als Basis für virtuelle Maschinen verwen-
den. Durch das von Ceph geleistete Striping
und die Verteilung der zugrunde liegenden
Objekte über viele OSDs hinweg lassen sich
dadurch sogar virtuelle Devices erstellen, die
schneller Daten lesen und schreiben als lokale
Festplatten das könnten.
CephFS: Bis hierher wurde voraus-
gesetzt, dass Anwendungen, die einen Ceph-
Cluster verwenden wollen, dies über die oben
genannten APIs tun, sofern sie nicht direkt auf
dem grundlegenden Low-Level-librados-API
aufsetzen wollen. Für viele Anwendungen gilt
dies jedoch nicht. Eine große Anzahl existie-
render Anwendungen fußt auf einer dateiba-
sierten Datenablage.
Um diesem Umstand Rechnung zu tragen
(und für Fälle, in denen explizit ein verteiltes
Dateisystem benötigt wird; zum Beispiel als
NFS-Alternative), steht mit CephFS ein verteil-
tes Dateisystem zur Verfügung, das unter der
Haube den Ceph-Cluster zur Speicherung der
eigentlichen Daten verwendet, Anwendungen
aber eine POSIX-konforme Dateisystemsicht
darauf anbietet. Es ist diesbezüglich vergleich-
bar mit anderen verteilten Dateisystemen wie
zum Beispiel Gluster.
CephFS wird wie andere Dateisysteme ge-
mountet. Dabei stehen sowohl ein Kernelm-
odul als auch ein FUSE-Dateisystem zur Wahl.
Abbildung 6 verdeutlicht den Zusammenhang
der Komponenten. CephFS setzt die Installati-
on eines oder mehrerer Ceph-Metadata-Ser-
ver (MDS) im Cluster voraus, um dateisystem-
typische Metadaten wie Ordnerstrukturen,
Berechtigungen oder Zeitstempel zu verwal-
ten. Zwar können Ceph-Objekte generell ne-
ben den eigentlichen Daten auch beliebige
zusätzliche Key-Value-Paare als Metadaten
speichern, jedoch ist deren Semantik nicht de-
Abbildung 6 -
Der Ceph MDS Daemon nutzt diese Key-Value
Tupel zur Speicherung der Dateisystemmeta-
daten, die in einer reinen Object-Store-Se-
mantik nicht vorkommen. Im Sinne schneller
Antwortzeiten werden diese Daten vom MDS
soweit wie möglich im RAM vorgehalten. Auf
diese Weise wird sichergestellt, dass einfache
Operationen wie Verzeichnis-Listings oder
Rechteprüfungen nicht an potenziell zahlrei-
che OSD Daemons weitergeleitet und die Er-
gebnisse wieder zusammengeführt werden
müssen. Wäre dies der Fall, hinge die Per-
formance solcher Operationen stark von der
sonstigen Auslastung des Netzwerks und der
OSDs ab.
CephFS und Pools: Die weiter oben be-
schriebenen Pools (mit ihren jeweiligen Ein-
stellungen bzgl. Redundanz und Striping) ste-
hen auch für CephFS zur Verfügung. Teile des
Verzeichnisbaums können konkreten Pools
zugeordnet werden. Alle Dateien, die in die-
sem Teil des Baums gespeichert werden, wer-
den im Cluster im entsprechenden Pool ab-
gelegt. Dadurch steht die mit Pools erreichte
Flexibilität auch dateibasierten Anwendungen
zur Verfügung.
CephFS-Hochverfügbarkeit: Während
ein einzelner Ceph MDS Daemon im Cluster
prinzipiell genügt, um CephFS nutzen zu kön-
nen, ist auch für diesen eine redundante Aus-
legung empfehlenswert, um einen weiteren
potenziellen Single Point of Failure zu vermei-
den. Es stehen sowohl Aktiv-Passiv- als auch
Daemons im Standby bereit, von denen einer
bei Ausfall der aktiven Instanz übernehmen
kann. Da die benötigten Daten ohnehin im
Storage-Cluster persistiert sind, ist dies ohne
Datenverluste leicht möglich und wird von
den Ceph-Monitoren übernommen.
wird das Management verschiedener Ab-
schnitte des gesamten CephFS-Verzeichnis-
baums von verschiedenen MDS Daemons
übernommen, um die Last zu verteilen. Auch
Kombinationen beider sind möglich, sodass
-
on aufgefangen werden können.
FAZIT
Ceph ist ein leistungsstarkes und robustes
Softwarepaket, das unter Verwendung von
kostengünstiger Standardhardware einen
und Striping – global oder pro Pool einstellbar
– ermöglichen eine feingranulare Kontrolle
über die Ressourcenverwendung. Die Verfüg-
barkeit sowohl objekt- als auch dateibasierter
Schnittstellen macht das System in einer Viel-
zahl von Szenarien einsetzbar.
Im Rahmen der Installation unseres Clusters
sowie mithilfe von Benchmarks [4] und ba-
sierend auf unserer bisherigen Erfahrung –
sowohl im Einsatz als Object Store für unse-
re eigene Anwendung, als auch als Basis für
die interne CenterDevice OpenStack Cloud
– konnten wir, im Unterschied zur bislang
eingesetzten Speicherlösung auf Basis von
Gluster, weder Performance- noch andere
nennenswerte Probleme erkennen. Testwei-
se herbeigeführte Ausfälle ganzer Knoten
wurden korrekt erkannt und behandelt und
die Komponenten vollautomatisch nach dem
Wiederverfügbarwerden in den Cluster integ-
riert.
Allerdings bringen Flexibilität und Mächtig-
keit eine steile Lernkurve bei der Installation
und Inbetriebnahme mit sich. Insbesondere
verlangt sie eine sorgfältige Planung und Um-
setzung der zugrunde liegenden Netzwerkin-
frastruktur, um die Kommunikation der OSD
14 15
Daemons untereinander sowie die mit Ceph-
Clients mit maximaler Geschwindigkeit zu ge-
währleisten. Wir planen für die Zukunft eine
deutliche Ausweitung der Einsatzfelder von
Ceph, insbesondere im Zusammenspiel mit
OpenStack. Gern sind wir bereit, Unterstüt-
zung bei der Planung und Umsetzung Ihrer
Ceph-Systeme anzubieten.
Links & Literatur
[1] http://ceph.com/papers/weil-crush-sc06.
pdf
[2] Alle Abbildungen wurden unverändert ge-
mäß CC-BY-SA-2.0 (https://creativecommons.
org/licenses/by-sa/2.0/) übernommen von
http://ceph.com/docs
[3] http://en.wikipedia.org/wiki/Paxos_(com-
puter_science)
[4] https://blog.codecentric.de/en/2014/03/
ceph-object-storage-fast-gets- benchmarking-
ceph/
Mit OpenStack eine eigene Cloud aufbauen
Privatsache
Die Abstraktion von einzelnen Servern, Festplatten und Netzwerkverbindungen zu allgemein verfügba-
ren Rechen- und Speicherressourcen ist die Grundidee des Cloud Computing. Amazon hat mit AWS [1]
-
wareplattform, mit der man sein „eigenes, privates Amazon“ aufbauen kann.
Cloud Computing entkoppelt Rechen- und Speicherressourcen von konkreter Hardware. Auf diese
Weise entsteht eine Abstraktionsschicht zwischen der Baremetal-Hardware und darauf laufenden
Softwarediensten. Durch die konsequente Virtualisierung aller Hardwarekomponenten wie CPU,
Speicher und Netzwerk wird es möglich, beliebige, virtuelle Infrastrukturen aufzubauen, ohne
schweißtreibende Änderungen am Cluster im Rechenzentrum durchführen zu müssen. Infrastruk-
tur wird damit zu einem Dienst – Infrastructure as a Service (IaaS), den man seinem Team oder
Kunden anbieten kann. Ein besonderer Vorteil von IaaS ist, dass Hardwareausfälle nicht sofort den
Ausfall der Softwaredienste bedeuten müssen. Durch Verlagerung der virtuellen Infrastruktur auf
noch funktionierende Baremetal-Hardware werden Ausfallzeiten minimiert.
OpenStack
OpenStack ist eine Linux-basierte Soft-
wareplattform, die ursprünglich von RackSpace
[3] und der amerikanischen Raumfahrtagentur
NASA [4] seit 2010 entwickelt wurde. Mittler-
weile wird OpenStack unter der Kontrolle der
OpenStack Foundation mit der Unterstützung
von über 200 Firmen weiterentwickelt; u. a.
von Cisco, Dell, HP, IBM, Intel, Oracle, Red Hat,
Suse, Ubuntu und VMware. Bei der Entwick-
lung von OpenStack wird besonderer Wert auf
die Kompatibilität mit Amazon AWS gelegt, so-
dass Anwendung und virtuelle Infrastrukturen
für AWS leicht auf OpenStack übertragbar sind.
Abbildung 1 zeigt den grundsätzlichen Aufbau
einer privaten Cloud mit OpenStack.
OpenStack ist kein einzelnes Softwareprodukt
wie etwa VMware vSphere, sondern eine mo-
dulare Softwareplattform zum Aufbau einer pri-
konkrete Anforderungen angepasst werden. Das
notwendig ist, um erfolgreich eine Cloud-Umge-
bung aufzusetzen. In diesem Artikel werden wir
OpenStack anhand der CenterDevice-Cloud vor-
stellen.
Abbildung 1 -
16 17
OpenStack bei CenterDevice
CenterDevice ist ein hochskalierbarer Cloud-
Dienst zum Verwalten, Teilen und Finden von
Dokumenten aller Art. Unsere Kunden sind
kleine und große Unternehmen sowie Behör-
den, die immer und überall auf ihre Doku-
mente zugreifen wollen. Ferner erlaubt Cen-
terDevice das Durchsuchen von gigantischen
Dokumentenmengen über Volltextindizierung
und verzichtet dabei auf undurchsichtige Ver-
zeichnisstrukturen.
Für unseren Cloud-Dienst ist es deswegen
erforderlich, leicht zu skalieren und mit Hard-
wareausfällen umzugehen, ohne dass unse-
re Kunden einen Serviceverlust bemerken.
OpenStack ist hierfür die beste Lösung, um
unserer verteilten Software eine stabile und
robuste Infrastruktur zu bieten. Unser aktu-
elles OpenStack-Cluster kann hierbei zwanzig
virtuelle Maschinen mitsamt virtuellem Netz-
werk in knapp 40 Sekunden starten. Ausfälle
eines Hardwareknotens werden ohne Unter-
brechung von den restlichen Knoten aufge-
fangen.
OpenStack-Versionen
Die Linux-Referenzdistribution für OpenStack
ist Ubuntu. OpenStack folgt wie Ubuntu ei-
nem sechsmonatigen Releasezyklus. Seit Ok-
tober 2013 ist das OpenStack-Havana-Release
für Ubuntu 12.04 LTS freigegeben. Im April ist
zeitgleich mit Ubuntu 14.04 LTS die jüngste
stabile Version von OpenStack mit dem Na-
OpenStack-Knotentypen
OpenStack unterscheidet drei Knotentypen:
Controller, Network und Compute Node. Die
Controller-Knoten beherbergen die internen
-
onsschnittstellen (sowohl für Konsole als auch
das Web-UI – siehe unten). Die Networkkno-
ten sind die Endpunkte für die virtualisierten
Netzwerke und stellen den Übergang von vir-
tuellen in physikalische Netzwerke her. Auf
Compute-Knoten laufen die tatsächlichen vir-
tuellen Maschinen.
OpenStack-Komponenten
Die OpenStack-Plattform besteht aus zehn
Komponenten – siehe Tabelle 1. OpenStack
ist voll multimandantenfähig. Das bedeutet,
dass man voneinander unabhängige virtuelle
Infrastrukturen aufbauen kann, die vollkom-
men isoliert ausgeführt werden. Dies erlaubt
-
ware durch verschiedene Teams und Kunden.
Man kann aber auch zum Beispiel leicht Pro-
Diese Isolation setzt eine konsequente Rech-
teverwaltung voraus. Die OpenStack-Kompo-
nente Keystone verwaltet hierbei alle Objekte,
wie Projekte, Netzwerke, virtuelle Maschinen
und Benutzer. Keystone muss immer instal-
liert werden.
Virtuelle Maschinen bestehen meist aus zwei
Komponenten: einem Image und einem vo-
latilen Speicher. Das Image ist das Template,
aus dem die virtuelle Maschine erzeugt wird.
Dafür dient der Glance-Dienst. Glance spei-
chert Images in verschiedenen Formaten je
nach ein- gesetztem Hypervisor – siehe weiter
unten. Unterstützt werden die Formate Raw,
AMI, VHD, VDI, qcow2, VMDK und OVF [5].
Um virtuellen Maschinen die Möglichkeit zu
geben, Daten zu schreiben, können Volumes
an eine virtuelle Maschine angehängt wer-
den. Diese Volumes werden als Block Storage
Devices, also reguläre Festplatten, durch den
Cinder-Dienst in die virtuelle Maschine einge-
blendet.
Die Speicherung von Images und Volumes
kann entweder mit klassischen Dateisystemen
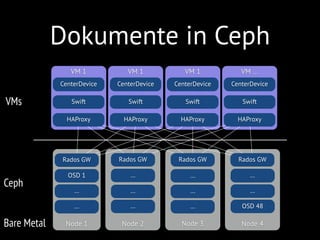
oder über den Dienst Swift erfolgen. Swift ist
als Object Store implementiert, der Daten be-
liebiger Art anhand eines Schlüssels ablegt.
Diese Form der Speicherung ist für größere
-
systeme und skaliert deutlich besser. Darü-
ber hinaus kann Swift auch an die virtuellen
Maschinen weitergereicht und dort als Object
Store für Anwendungen genutzt werden. Für
die CenterDevice-Cloud haben wir uns ent-
schieden, statt Swift Ceph [6] als Object Store
zu nutzen (Kasten: „Object Store mit Ceph“).
Das Verteilen auf die Computing-Knoten und
das Ausführen von virtuellen Maschinen erle-
digt die Open- Stack-Komponente Nova. Sie ist
das Herzstück von OpenStack und unterstützt
eine Vielzahl von Hypervisors. Darunter sind
KVM/QEMU, Xen, LXC/Docker und VMware.
Der Kasten „Wahl eines Hypervisors“ schildert,
warum wir bei CenterDevice KVM einsetzen.
18 19
Neutron ersetzt seit OpenStack Havana die
Nova-basierte Virtualisierung von Netzwer-
ken. Neutron verfolgt dabei das Konzept des
Whitepaper [8] bzw. Einführungsvortrag [9]
bei YouTube. Mit Neutron lassen sich nahezu
beliebig komplizierte Netzwerke auf Ebene 2
und 3 aufbauen. Es ist also möglich, getrennte
Netzwerke aufzubauen und diese mithilfe von
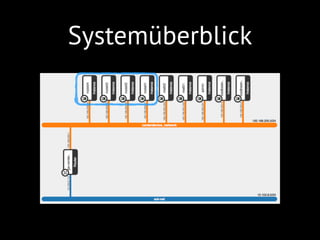
Routen zu verbinden. Abbildung 2 zeigt den
prinzipiellen Aufbau eines Neutron-basierten
Netzwerks mit zwei voneinander isolierten
Mandanten bzw. Projekten.
In dieser Abbildung ist zu sehen, dass die bei-
den Mandantennetzwerke (Tenant Networks)
-
guration des Routers entscheidet hierbei, ob
die beiden Netzwerke miteinander bzw. mit
dem Internet kommunizieren dürfen oder
nicht.
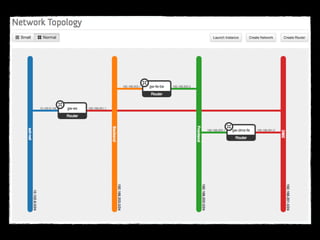
Abbildung 3 zeigt ein konkretes Netzwerk für
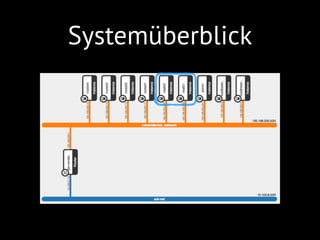
das Projekt Java Magazin, dargestellt im Hori-
zon Dashboard – siehe unten. Es werden vier
Netzwerke abgebildet, die der klassischen
Aufteilung in eine DMZ (rot), ein Frontend-
(grün) und ein Backend-Netzwerk (orange)
folgen. Das blaue Netzwerk spielt eine beson-
dere Rolle. Es stellt das so genannte externe
Netzwerk dar, das die virtuelle Welt mit der
physischen verbindet.
Über dieses Netzwerk können die virtuellen
Maschinen nach außen kommunizieren – sie-
he in Abbildung 2 das Providernetwork.
Die IP-Subnetze der virtuellen Netzwerke sind
alle private Netzwerke. Soll eine virtuelle Ma-
schine von außen erreichbar sein, so muss zu-
IP genannt – eine so genannte Floating- IP ver-
geben werden. Floating-IPs sind IP-Adressen,
die über Network Adress Translation (NAT)
von einer virtuellen Maschine zur anderen
-
werk stammen. Sie werden dynamisch von
OpenStack vergeben. Mithilfe dieser Floating-
IPs ist es möglich, einen Dienst hinter einer
solchen IP zu betreiben und sie im laufenden
Betrieb von einer auf eine andere virtuelle
Maschine zu migrieren; zum Beispiel, um eine
neue Version seiner Software zu aktivieren
oder einen Knoten zu ersetzen. Im Beispiel
aus Abbildung 3 haben die beiden Load Ba-
lancer am roten DMZ-Netzwerk von außen
erreichbare Floating-IPs. Floating-IPs stellen
jedoch eine besondere Herausforderung dar,
wenn die damit verbundenen Dienste von
anderen Knoten genutzt werden, da sie sich
ändern können (Kasten: „Dynamische Provisi-
onierung mit Metadaten“).
Abbildung 2 -
Abbildung 3 -](https://image.slidesharecdn.com/privatecloudmitopensource-140823052105-phpapp02/85/Private-Cloud-mit-Open-Source-59-320.jpg)





Das Dokument behandelt den Aufbau und die Vorteile einer flexiblen und leistungsfähigen Private Cloud mit Open Source-Technologien wie OpenStack und Ceph. Es beschreibt die grundlegenden Konzepte und technischen Details dieser Technologien, deren Anwendung in der Praxis und hebt die Vorteile in Bezug auf Datensicherheit, Ressourcenmanagement und Skalierbarkeit hervor. Abschließend wird auf die Herausforderungen bei der Implementierung verwiesen und die Expertise der Autoren in diesem Bereich betont.




































