Downloaden Sie, um offline zu lesen


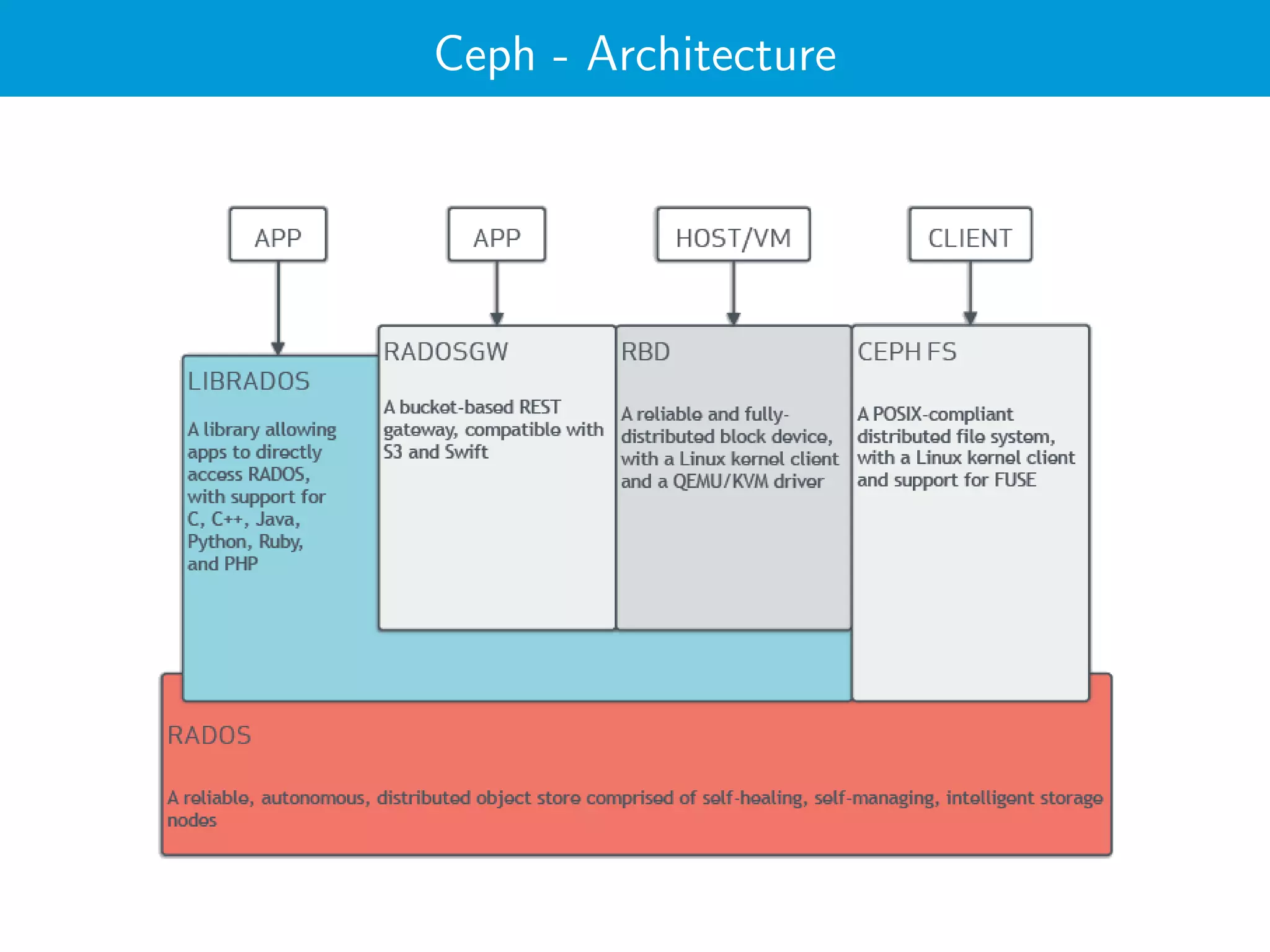

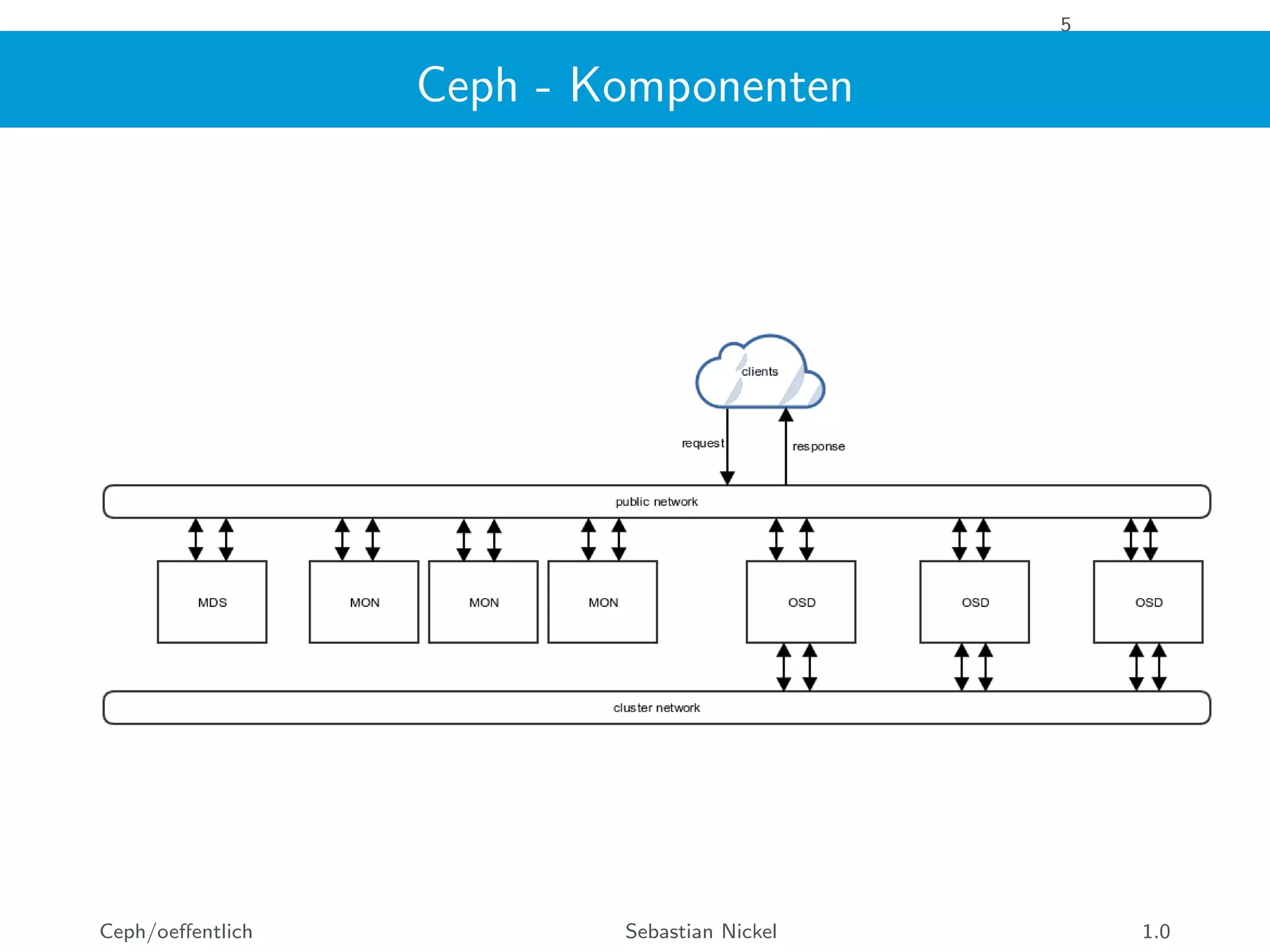





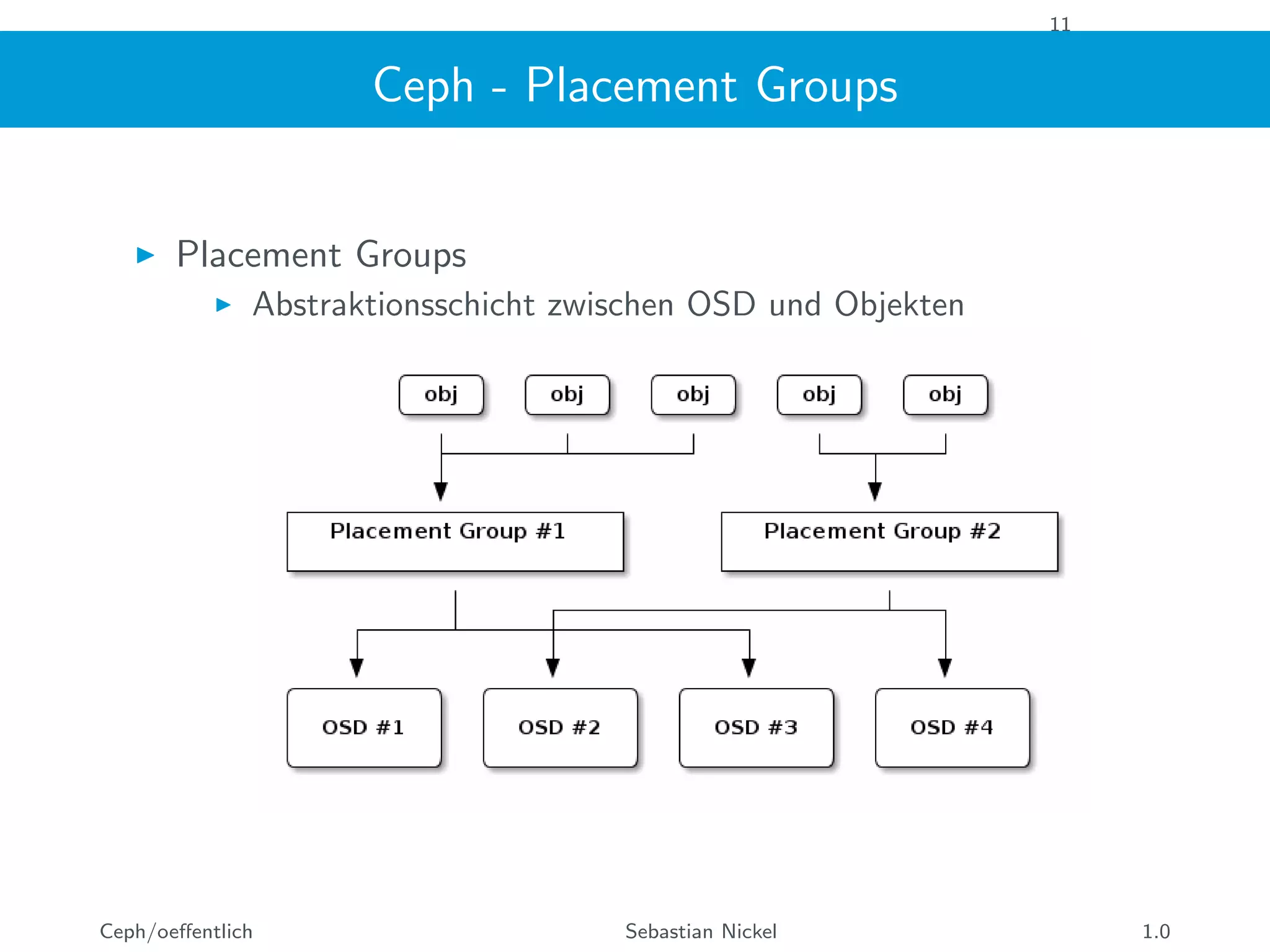




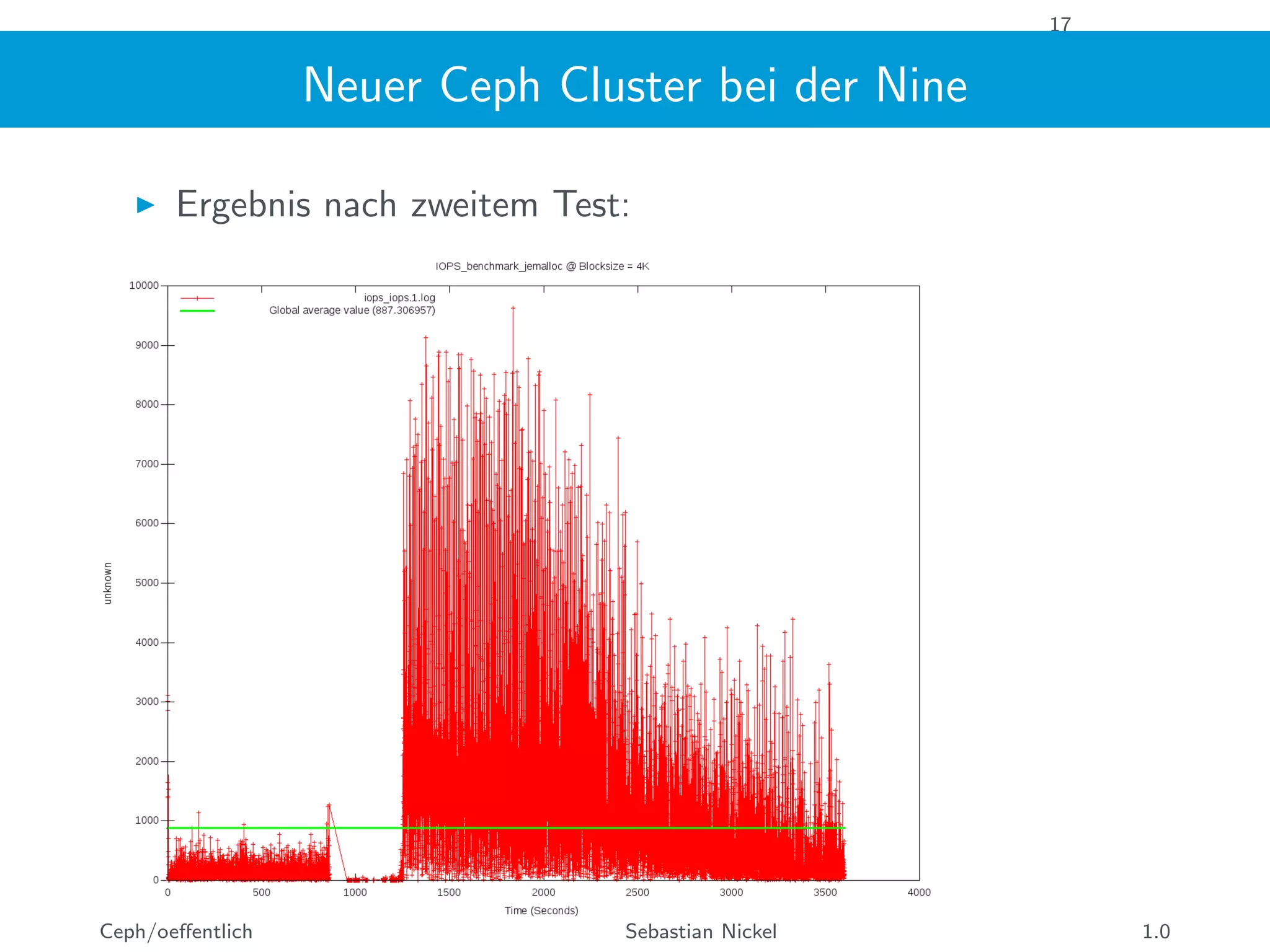













Das Dokument beschreibt Ceph, ein verteiltes Speichersystem, das Objekte auf mehreren Servern speichert und sowohl als Block- als auch als Dateispeicher fungiert. Es beleuchtet die Architektur, Eigenschaften und Komponenten von Ceph, einschließlich Monitoren, OSDs und dem CRUSH-Design, sowie spezifische Benchmarks und Leistungsanalysen eines neuen NVMe-Clusters. Abschließend wird festgestellt, dass eine VM die Geschwindigkeit von NVMe-Geräten nicht vollständig nutzen kann und die Parallelisierung entscheidend ist.


























































