Als PDF, PPTX herunterladen



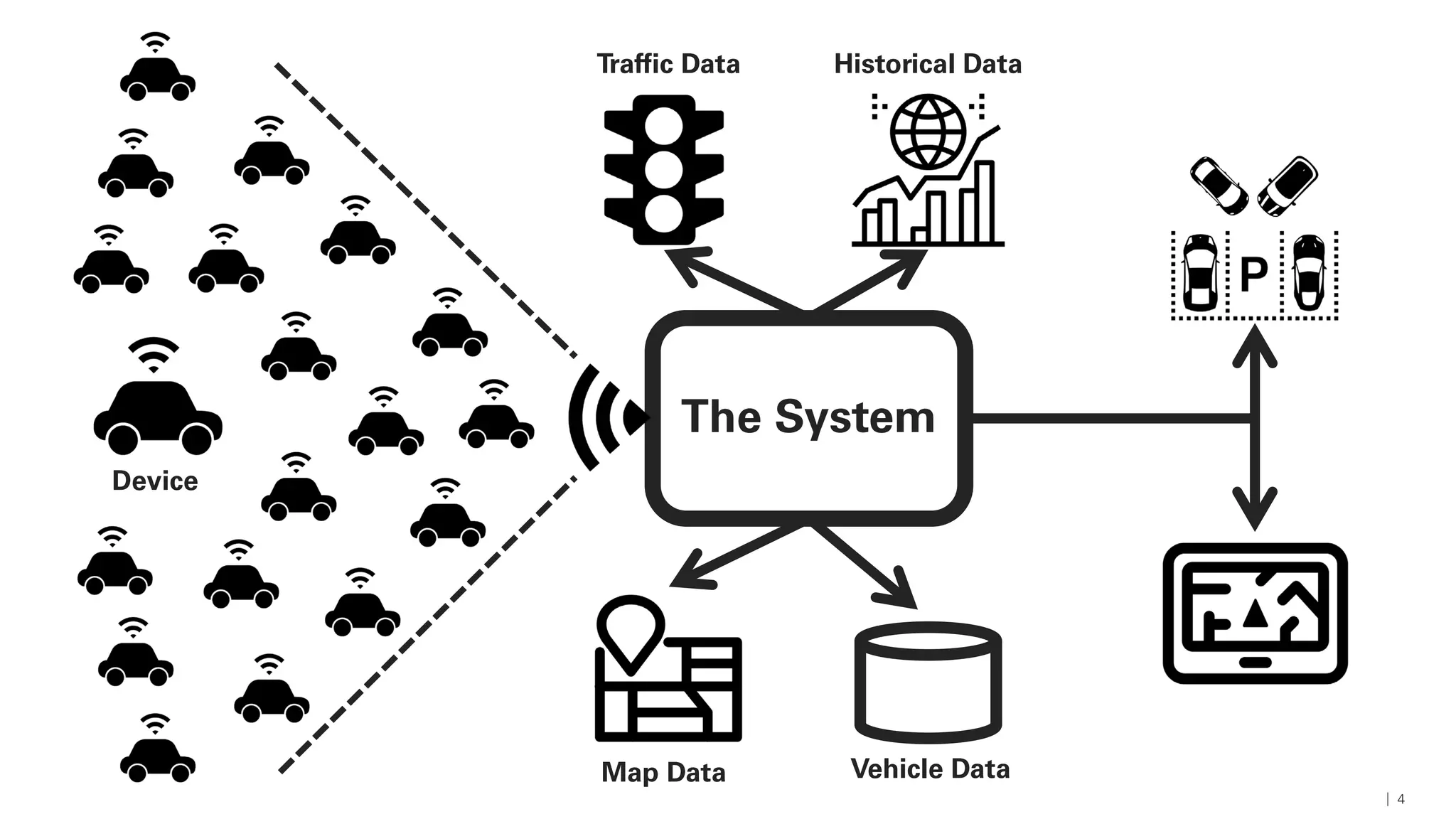

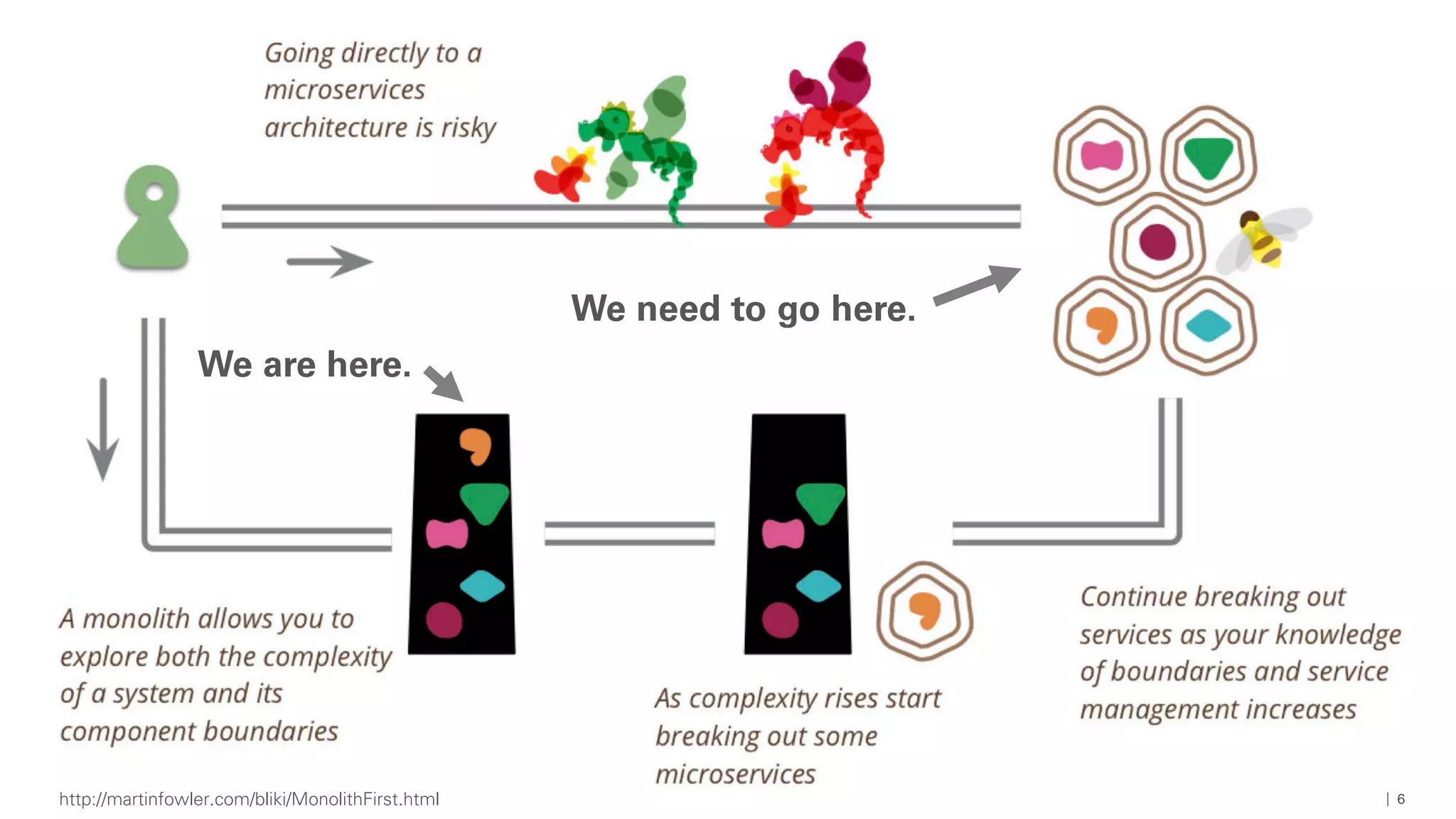


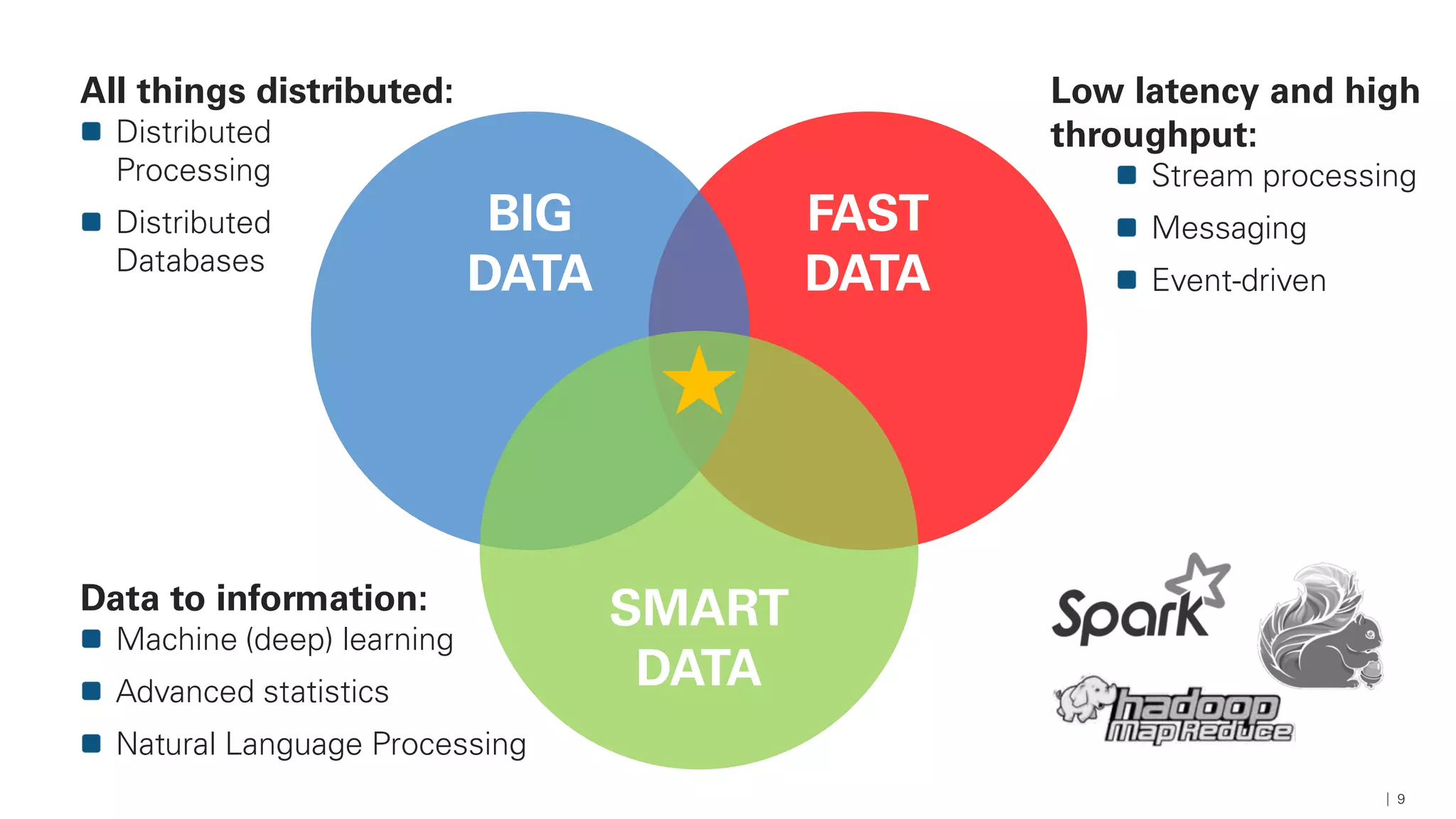
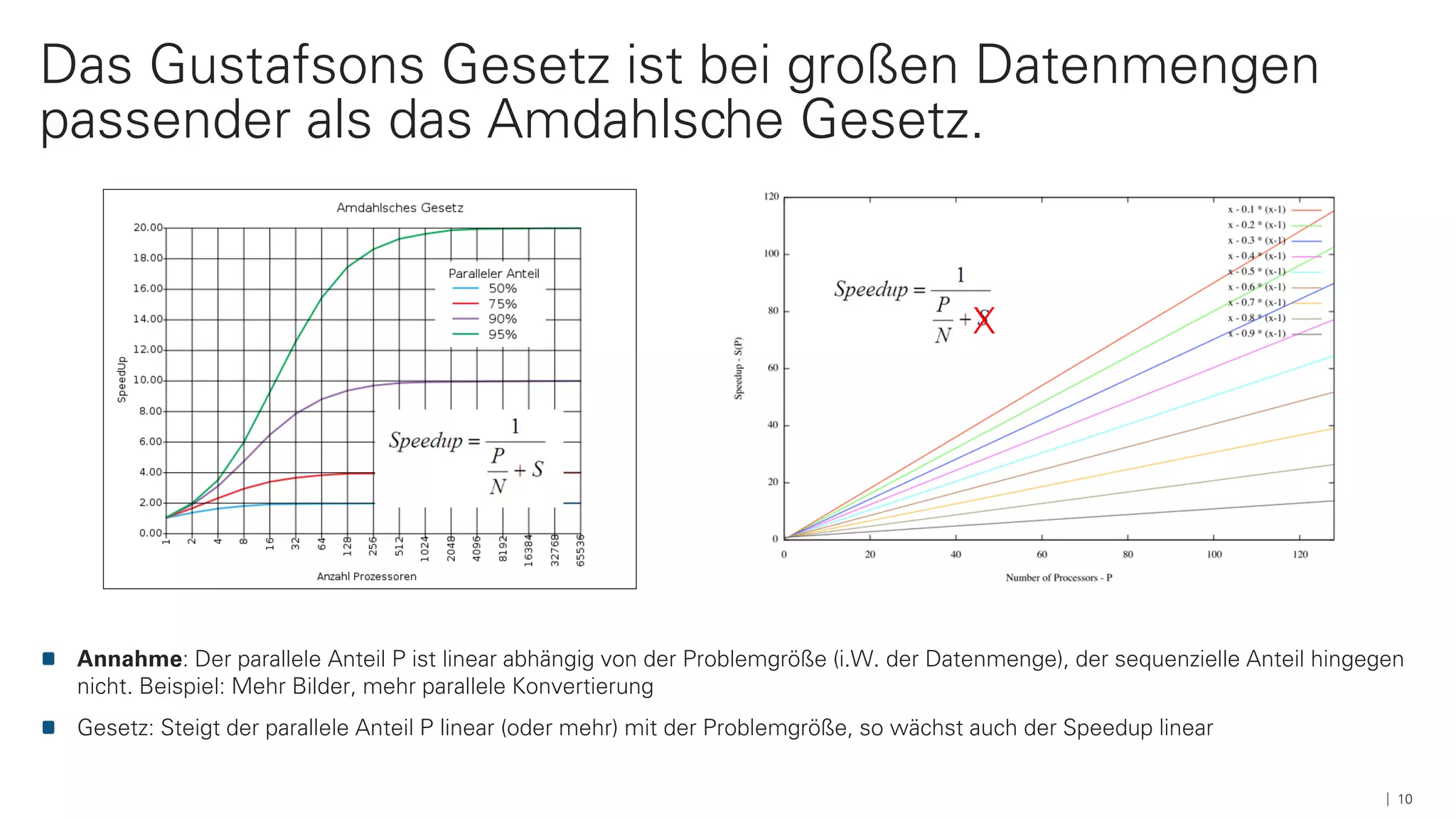

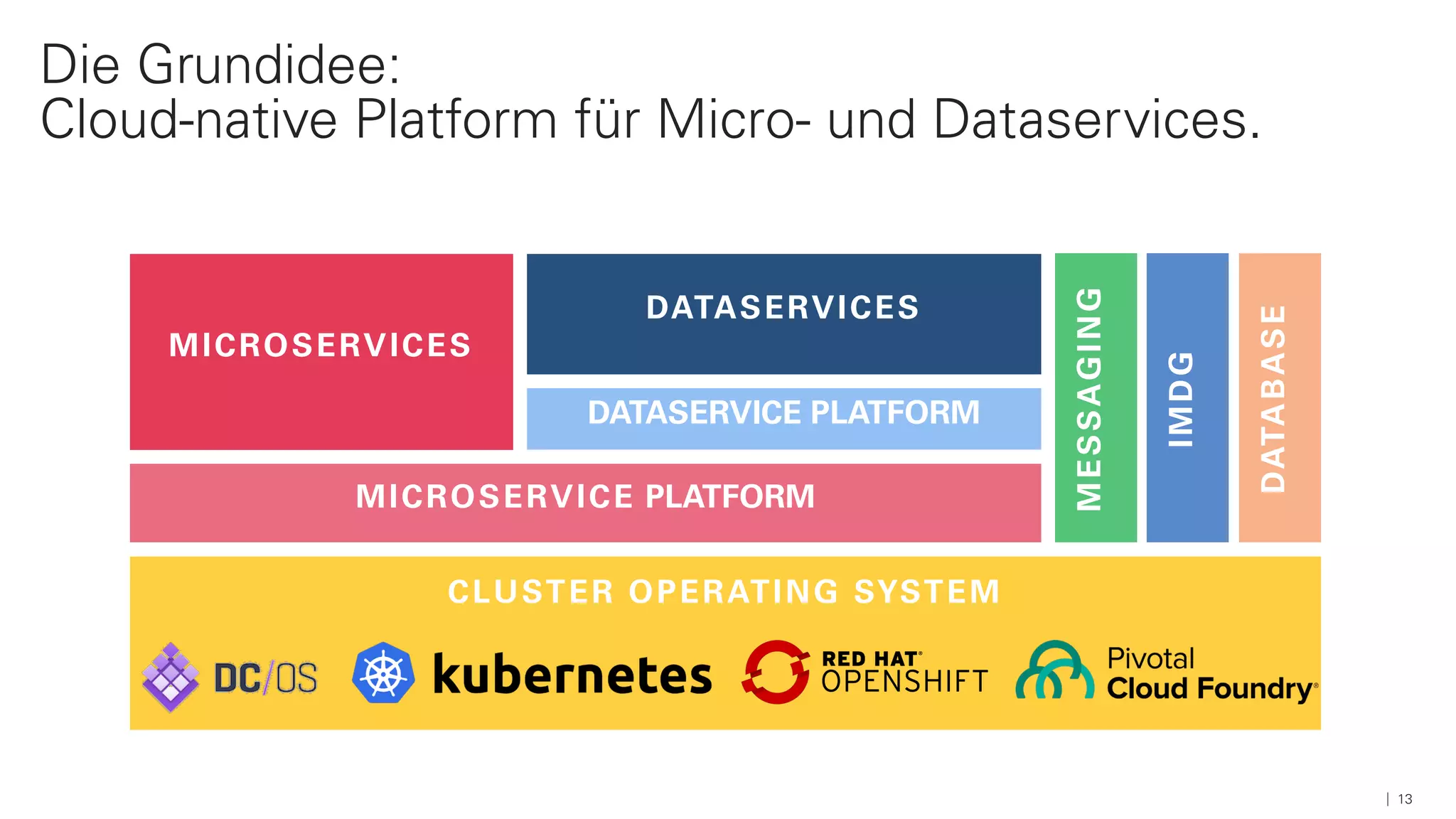

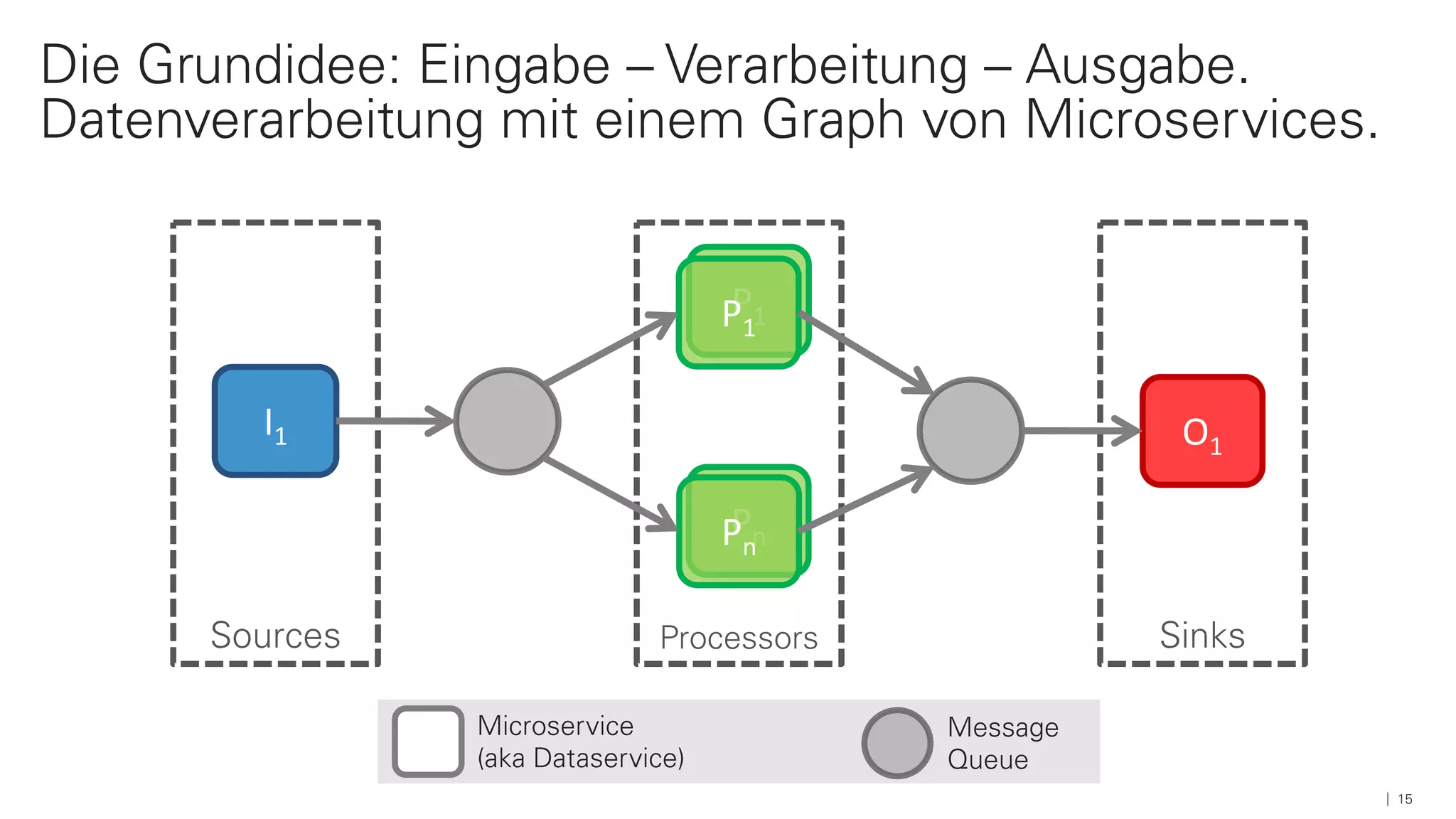


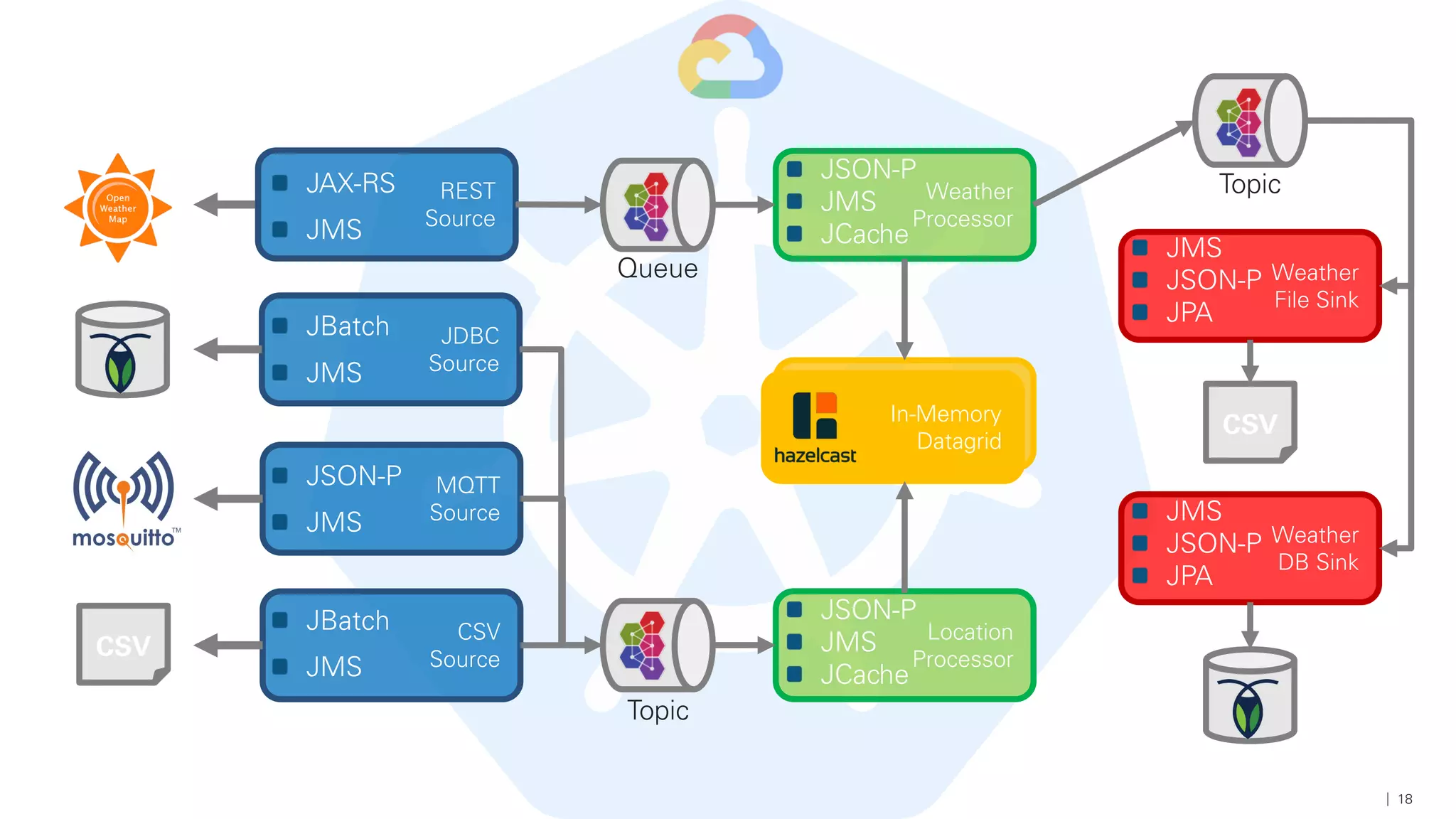


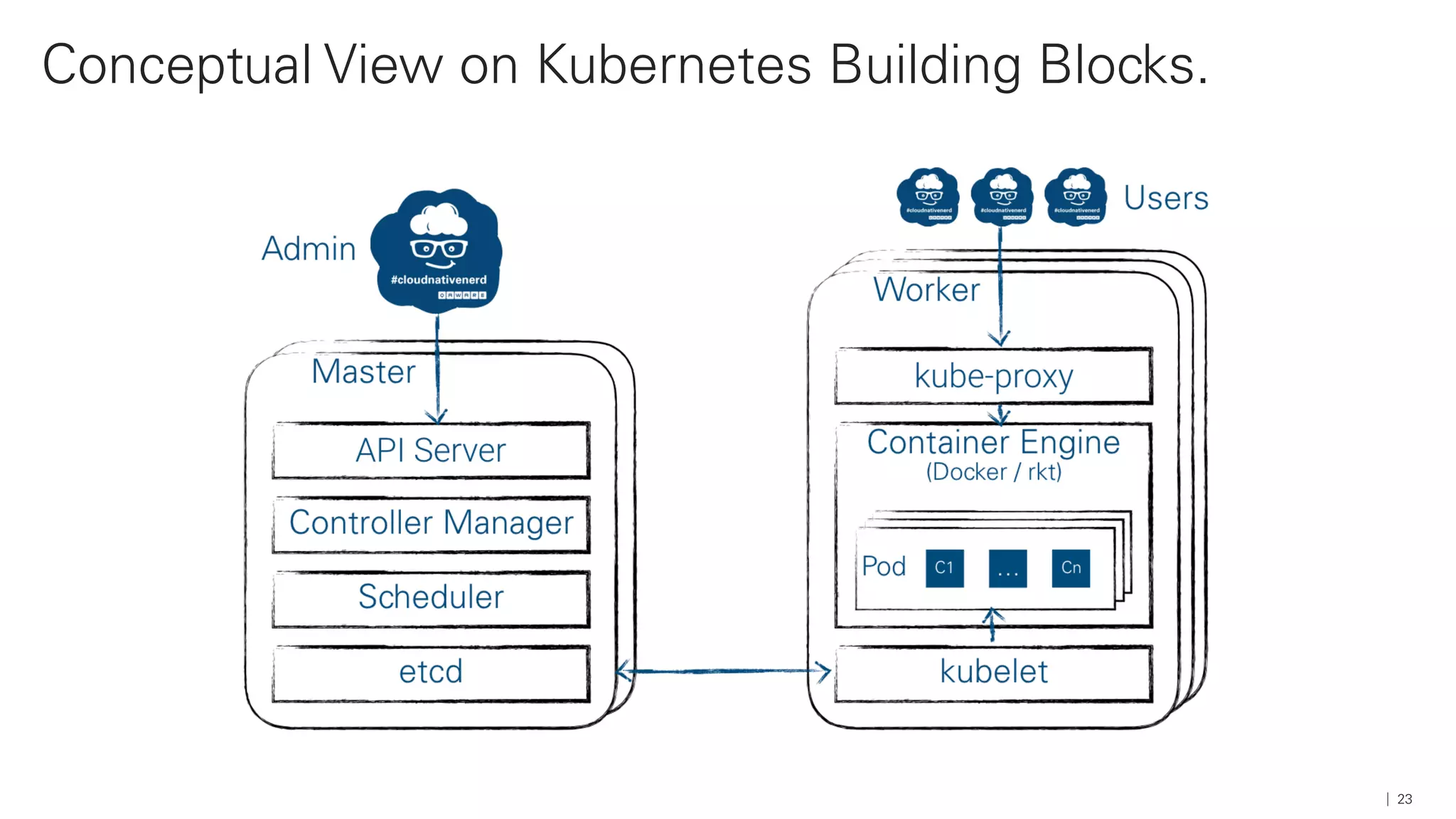
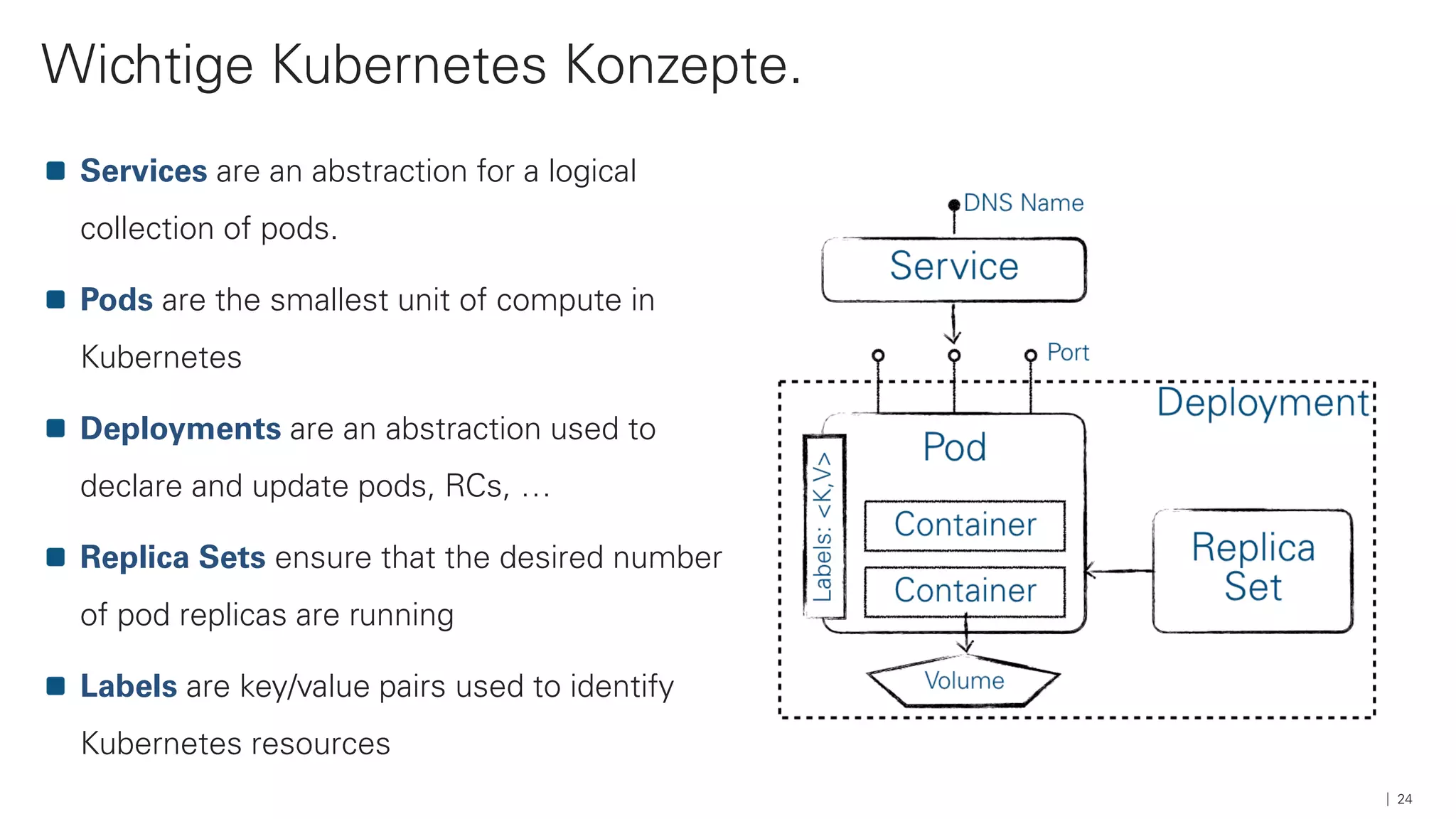





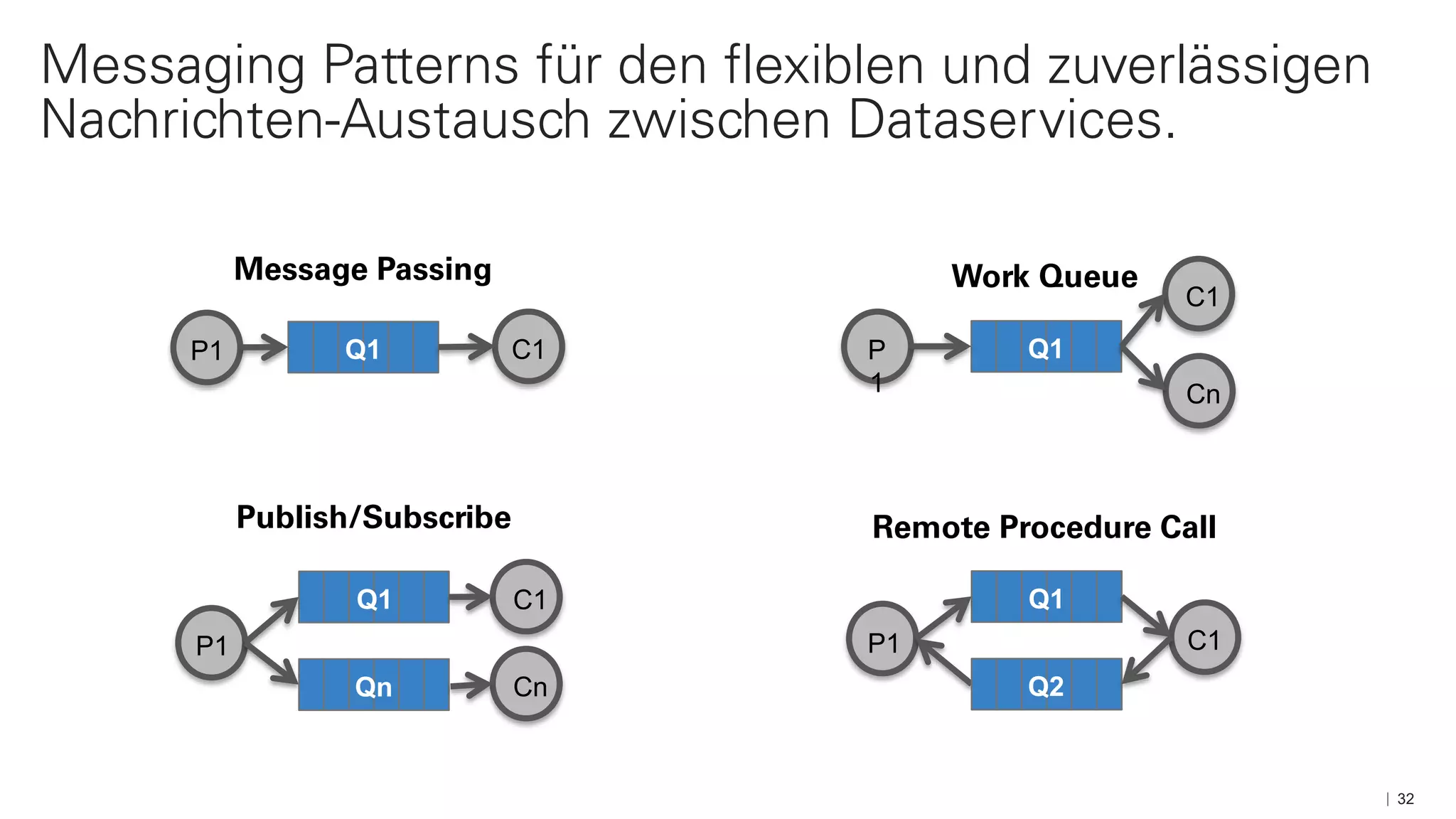

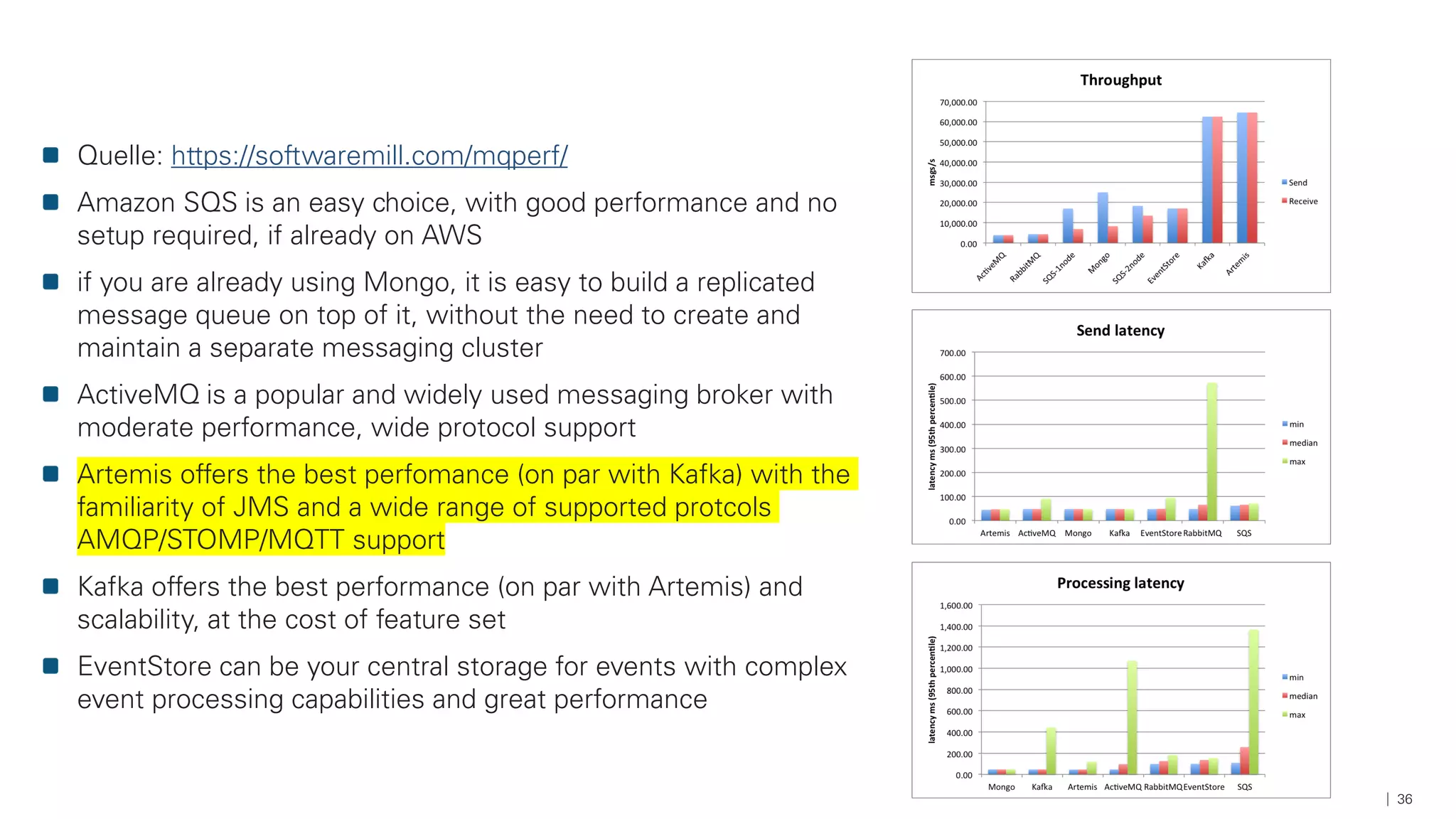
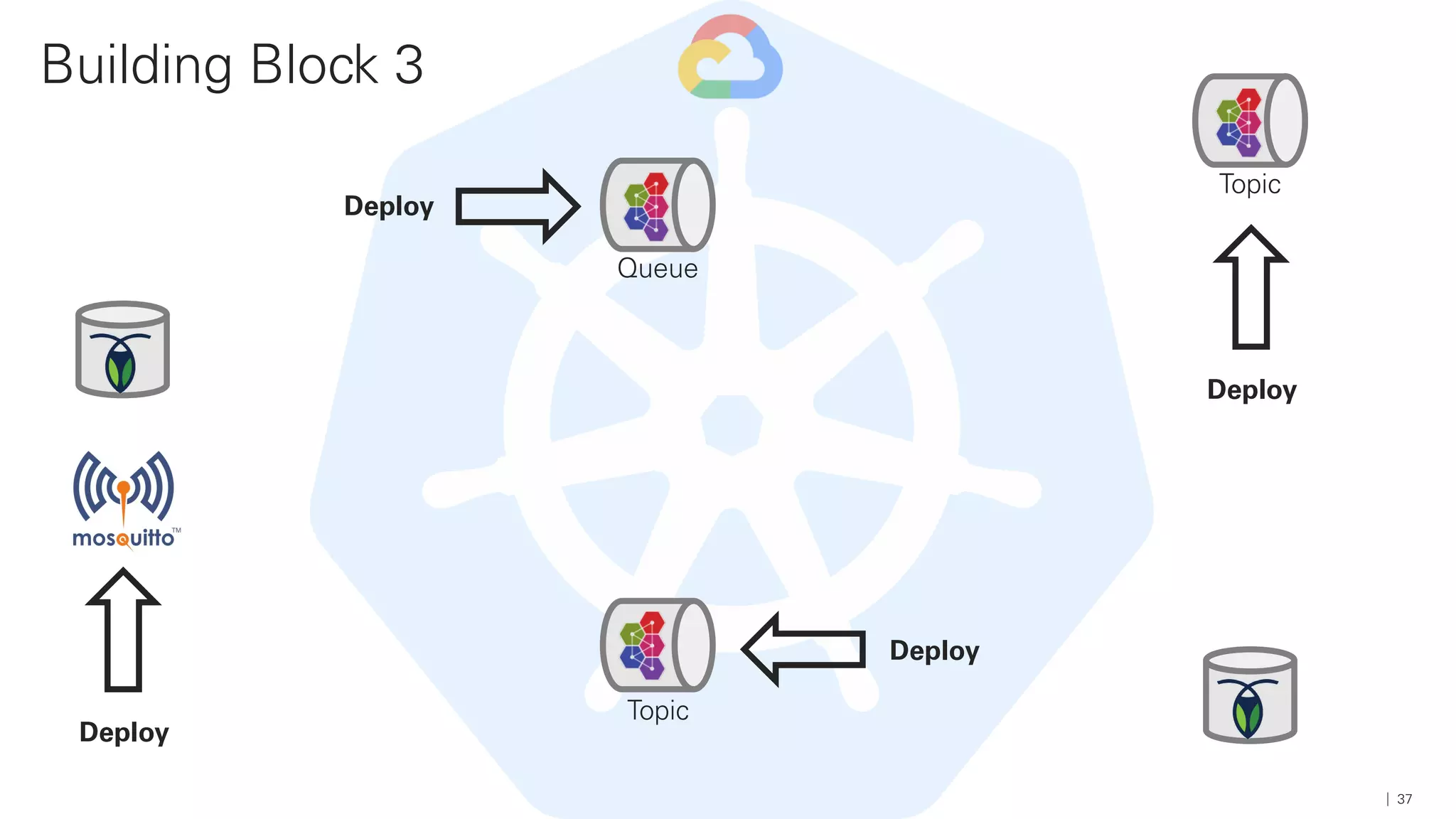



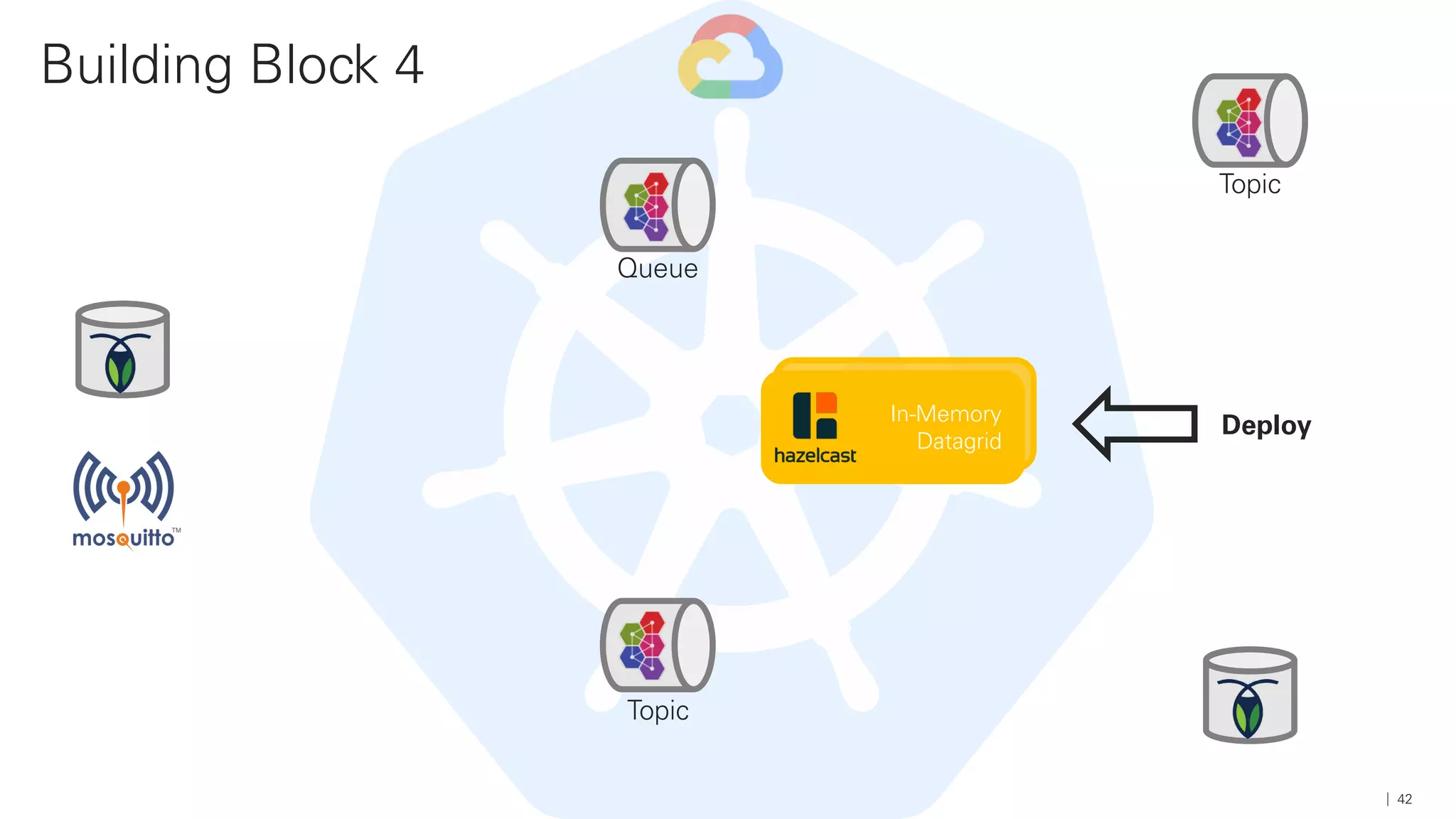


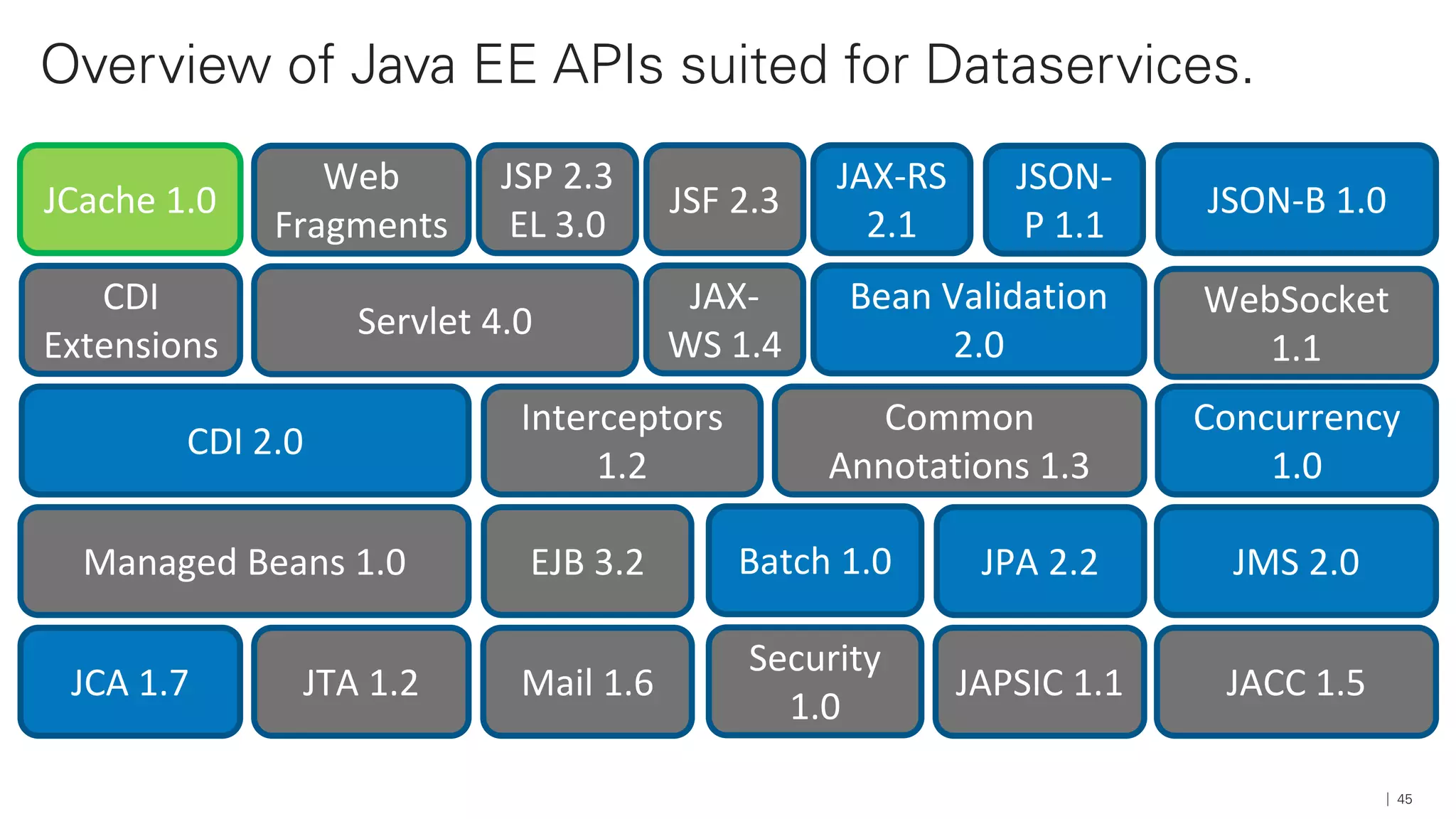

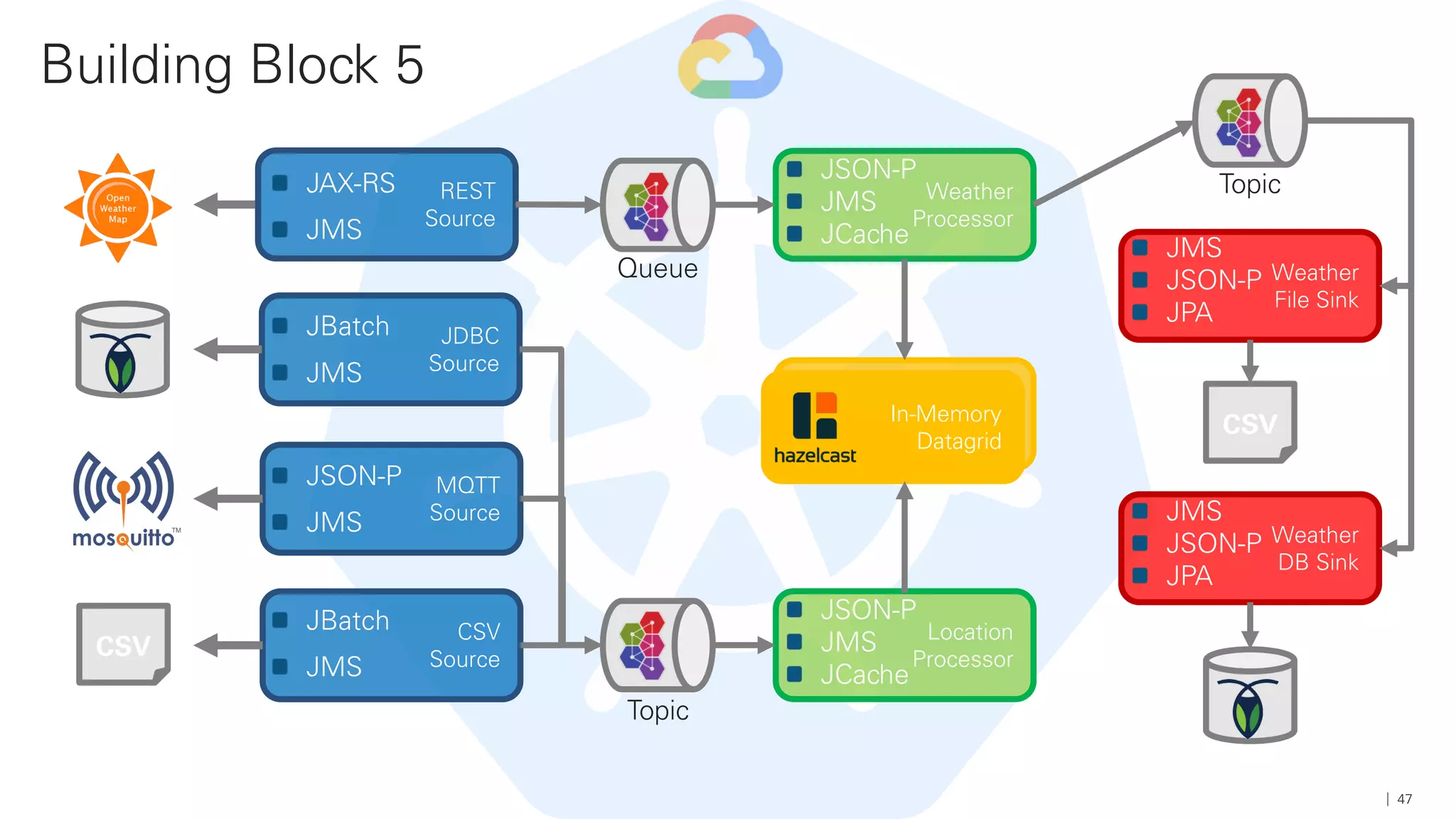



Das Dokument beschreibt die Architektur und Komponenten einer cloud-nativen Plattform für Daten- und Microservices, einschließlich der Nutzung von Microservices, Messaging-Infrastruktur und Datenbanken. Es werden Ansätze zur Verarbeitung von Big Data, Zuverlässigkeit und Fehlerresilienz in Pipelines sowie verschiedene Unterstützungssysteme und -protokolle durch bedeutende Technologien wie Kubernetes und Kafka behandelt. Weitere Bausteine umfassen die Integration von In-Memory-Daten, die Verwaltung von Microservices und die Nutzung von Open-Source-Lösungen für die Umsetzung dieser Technologien.























































