










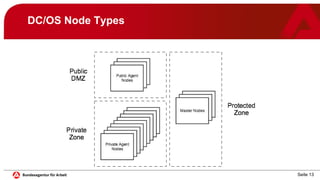
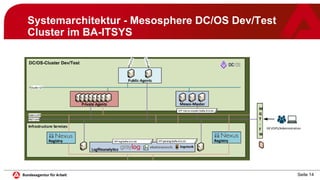
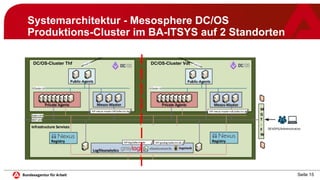



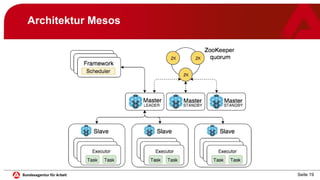


















Das Dokument behandelt die Implementierung und den Betrieb von Microservices und Container-Management mit Mesosphere DC/OS im IT-Systemhaus der Bundesagentur für Arbeit. Es beschreibt die Systemarchitektur, Betriebsempfehlungen, Sicherheitsaspekte und Lessons Learned aus einem Jahr Produktionsbetrieb. Es wird betont, dass die Technologie zuverlässig ist und eine gute Akzeptanz in der Entwicklung erreicht wurde, jedoch auch die Notwendigkeit von Automatisierung und standardisierten Vorgehensweisen hervorgehoben.







































