Downloaden Sie, um offline zu lesen










![HBase - Datendesign
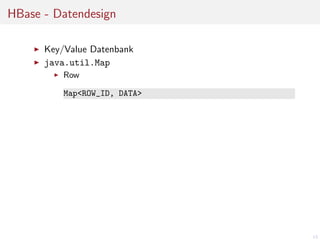
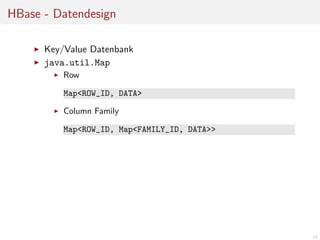
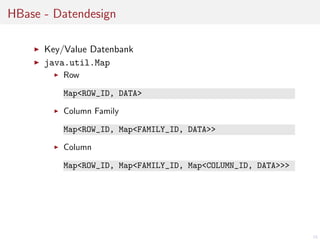
Key/Value Datenbank
java.util.Map
Row
Map<ROW_ID, DATA>
Column Family
Map<ROW_ID, Map<FAMILY_ID, DATA>>
Column
Map<ROW_ID, Map<FAMILY_ID, Map<COLUMN_ID, DATA>>>
Alle Werte sind byte[]
Map<byte[], Map<byte[], Map<byte[], byte[]>>>
16](https://image.slidesharecdn.com/roelofsenhbaseweb-140221081455-phpapp01/85/Webanwendungen-mit-Apache-HBase-entwickeln-16-320.jpg)


![HBase - Versionierung
Jede ”Zelle” wird mit einem Timestamp gespeichert und
automatisch versioniert
Map<byte[], Map<byte[], Map<byte[], Map<Long, byte[]>>>>
22](https://image.slidesharecdn.com/roelofsenhbaseweb-140221081455-phpapp01/85/Webanwendungen-mit-Apache-HBase-entwickeln-22-320.jpg)
![HBase - Versionierung
Jede ”Zelle” wird mit einem Timestamp gespeichert und
automatisch versioniert
Map<byte[], Map<byte[], Map<byte[], Map<Long, byte[]>>>>
Default: 3 Versionen
Timestamp wird beim Schreiben vom Server gesetzt,
kann aber vom Client uberschrieben werden
¨
23](https://image.slidesharecdn.com/roelofsenhbaseweb-140221081455-phpapp01/85/Webanwendungen-mit-Apache-HBase-entwickeln-23-320.jpg)

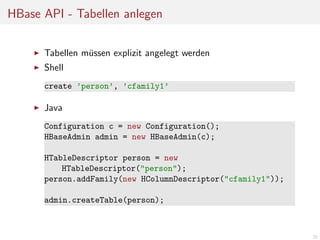
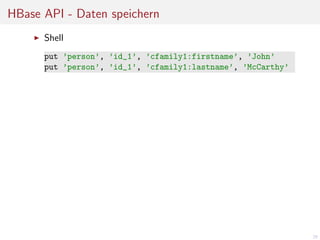
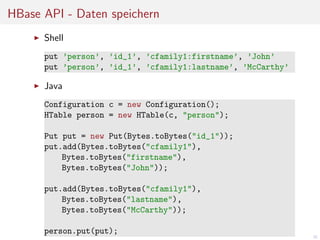
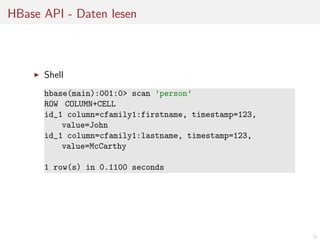
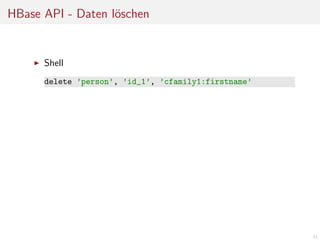
![HBase API - Daten lesen
Java
Configuration c = new Configuration();
HTable person = new HTable(c, "person");
Get get = new Get(Bytes.toBytes("id_1"));
get.addColumn(Bytes.toBytes("cfamily1"),
Bytes.toBytes("firstname"));
get.addColumn(Bytes.toBytes("cfamily1"),
Bytes.toBytes("lastname"));
Result result = person.get(get);
byte[] firstname =
result.getValue(Bytes.toBytes("cfamily1"),
Bytes.toBytes("firstname"));
..
32](https://image.slidesharecdn.com/roelofsenhbaseweb-140221081455-phpapp01/85/Webanwendungen-mit-Apache-HBase-entwickeln-32-320.jpg)

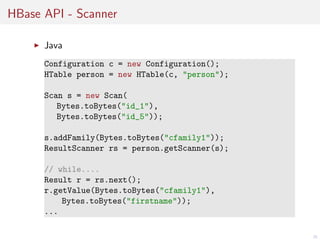




![Atomare Operationen, Isolierung
Batch-Support
List<Row> ops = new LinkedList<Row>();
Put put1 = new Put(Bytes.toBytes("id1");
put1.add(Bytes.toBytes("cf"), Bytes.toBytes("col"),
Bytes.toBytes("abc"));
ops.add(put1);
Put put2 = new Put(Bytes.toBytes("id2");
put2.add(Bytes.toBytes("cf"), Bytes.toBytes("col"),
Bytes.toBytes("def"));
ops.add(put12;
Object[] result = new Object[ops.size()];
table.batch(ops, result);
40](https://image.slidesharecdn.com/roelofsenhbaseweb-140221081455-phpapp01/85/Webanwendungen-mit-Apache-HBase-entwickeln-40-320.jpg)












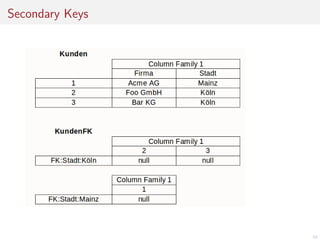
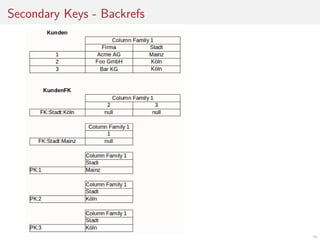



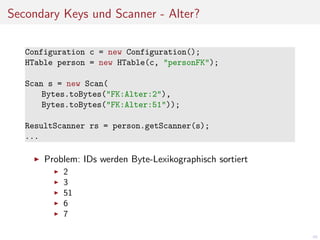














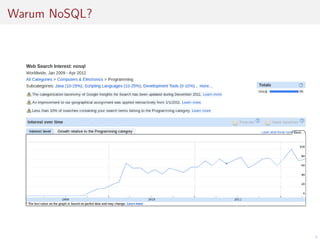
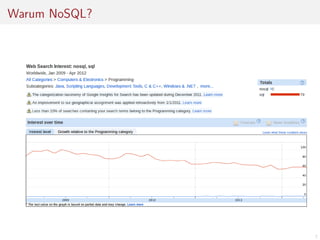
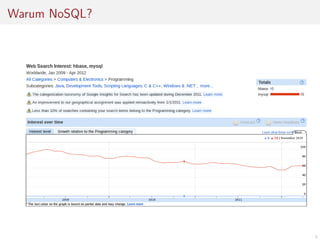
Das Dokument befasst sich mit der Entwicklung von Webanwendungen mithilfe von Apache HBase und erläutert die Vorteile von NoSQL-Datenbanken gegenüber traditionellen RDBMS, insbesondere hinsichtlich der horizontalen Skalierbarkeit. Es beschreibt die Architektur von HBase, einschließlich Datendesign, Versionierung und Nutzung von APIs, sowie die Herausforderungen bei der Synchronisation in Multi-User-Umgebungen. Abschließend werden Vor- und Nachteile von HBase thematisiert und praktische Tipps zur Implementierung gegeben.






























![Google apps and Python para Python Brasil [7]](https://cdn.slidesharecdn.com/ss_thumbnails/appspresent-111001102321-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















