14-mal heruntergeladen



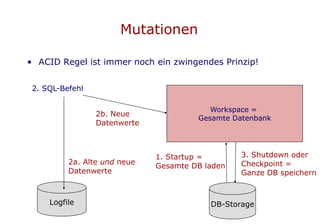



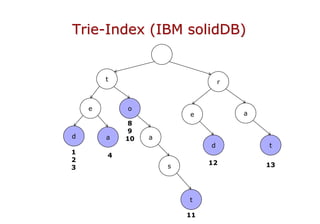









In-Memory-Datenbanken ermöglichen es, die gesamte Datenbank im Hauptspeicher zu halten, was zu schnelleren Zugriffen und der Eliminierung von Disk-I/O führt. Durch neue Indexierungsstrukturen wie T-Tree und Trie wird die Effizienz beim Datenzugriff signifikant erhöht. Diese Technologien erfordern jedoch ausreichend physikalischen Speicher, um eine optimale Leistung zu gewährleisten.










































