Downloaden Sie, um offline zu lesen

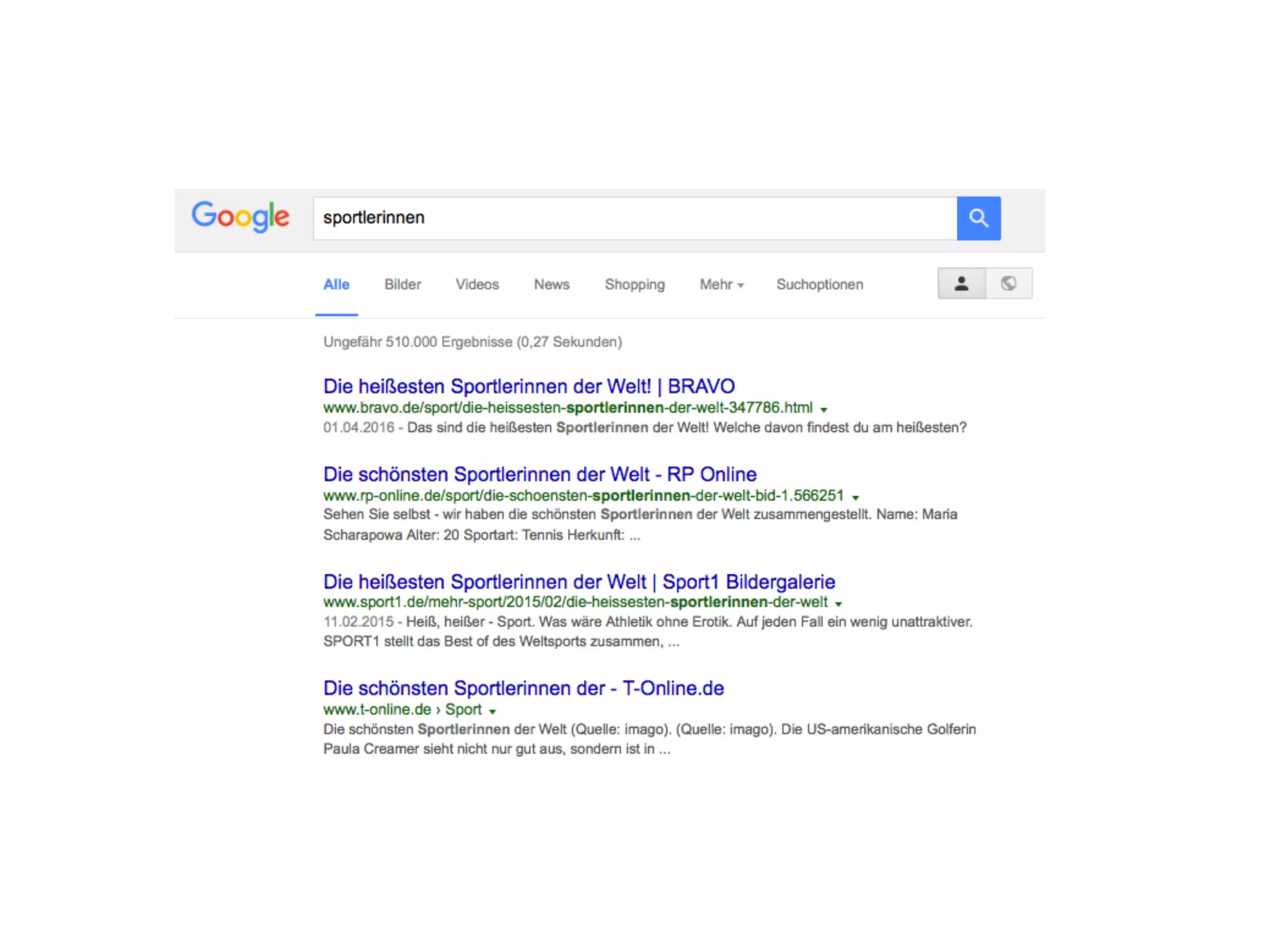







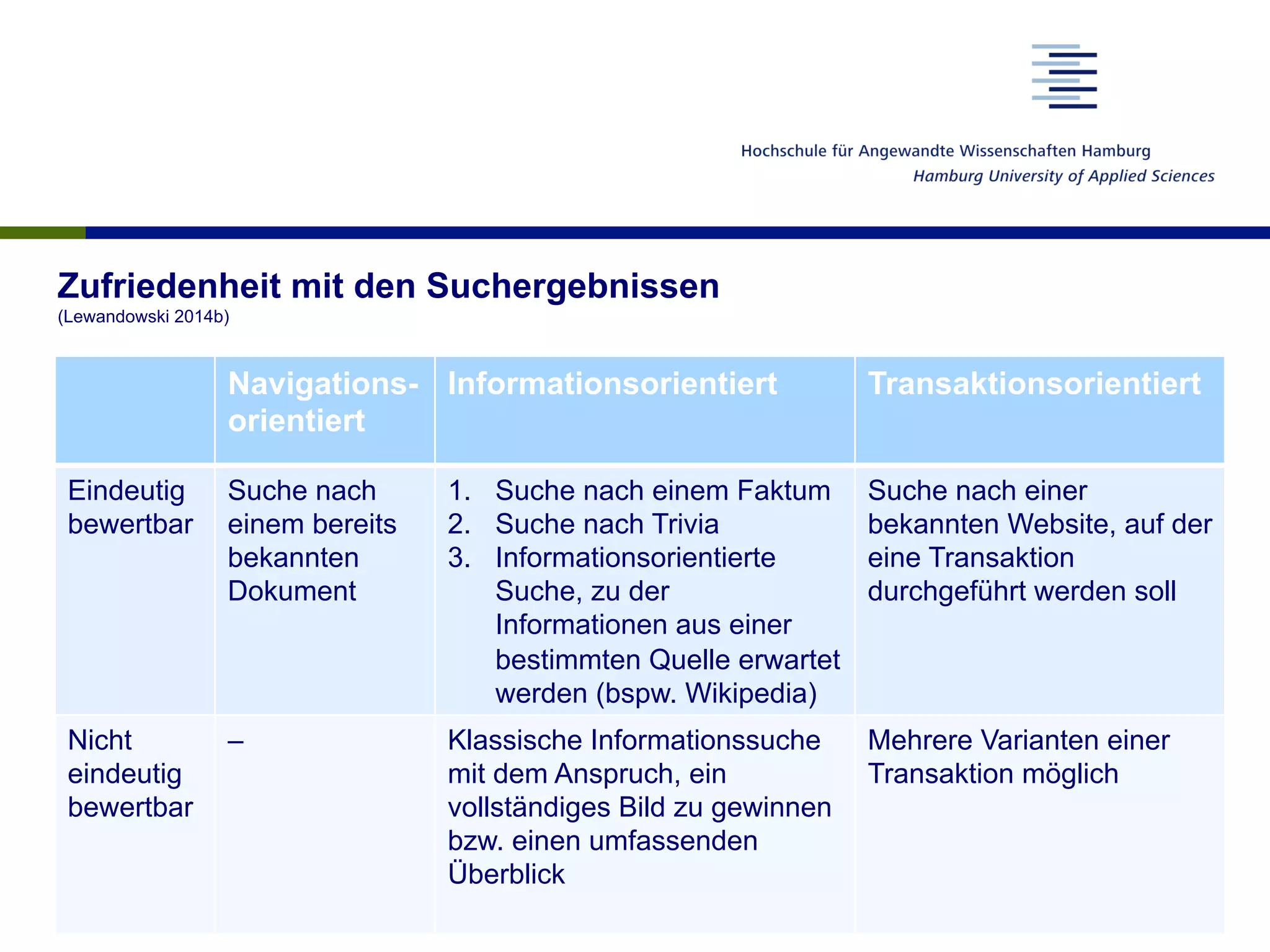


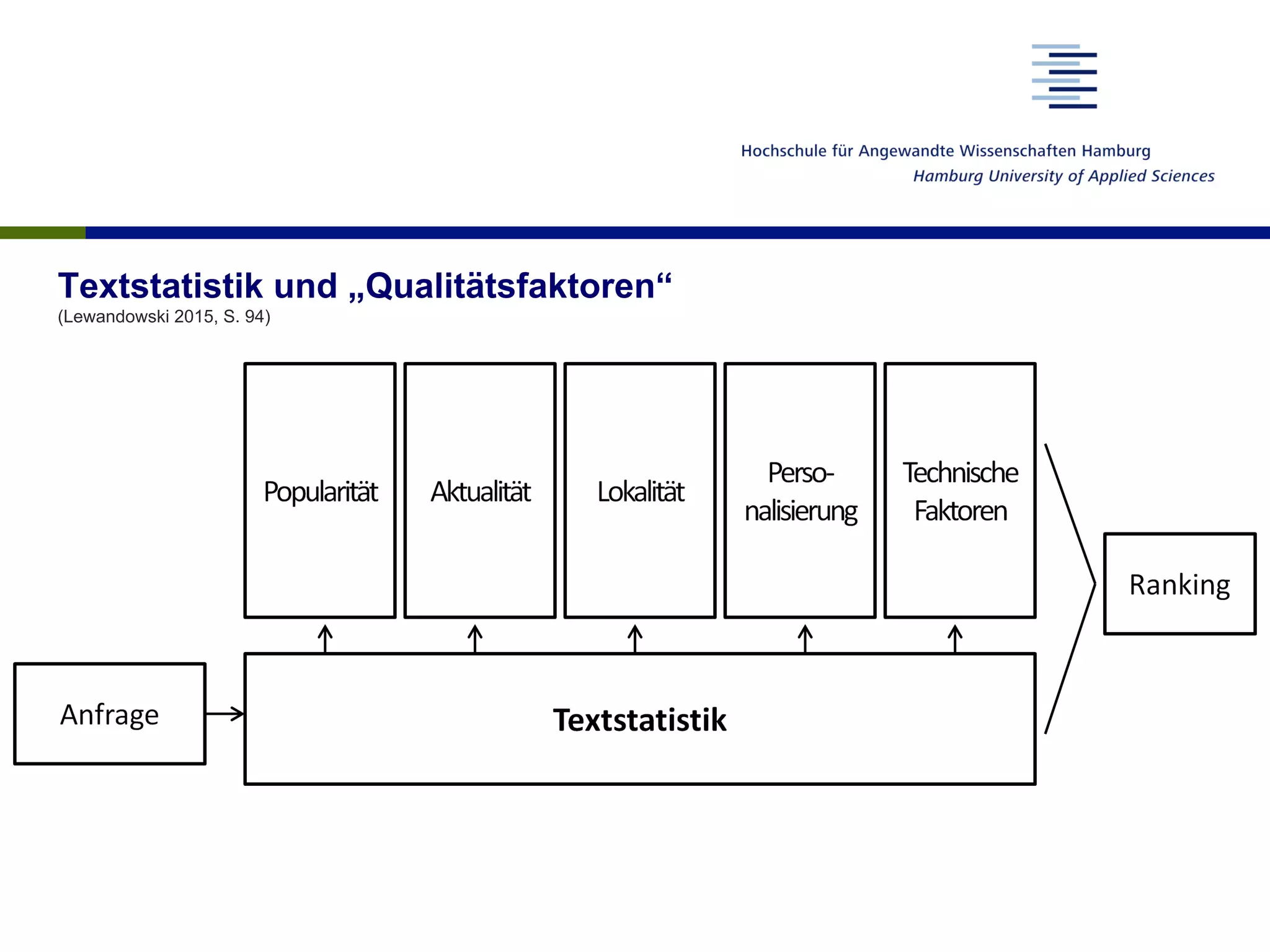




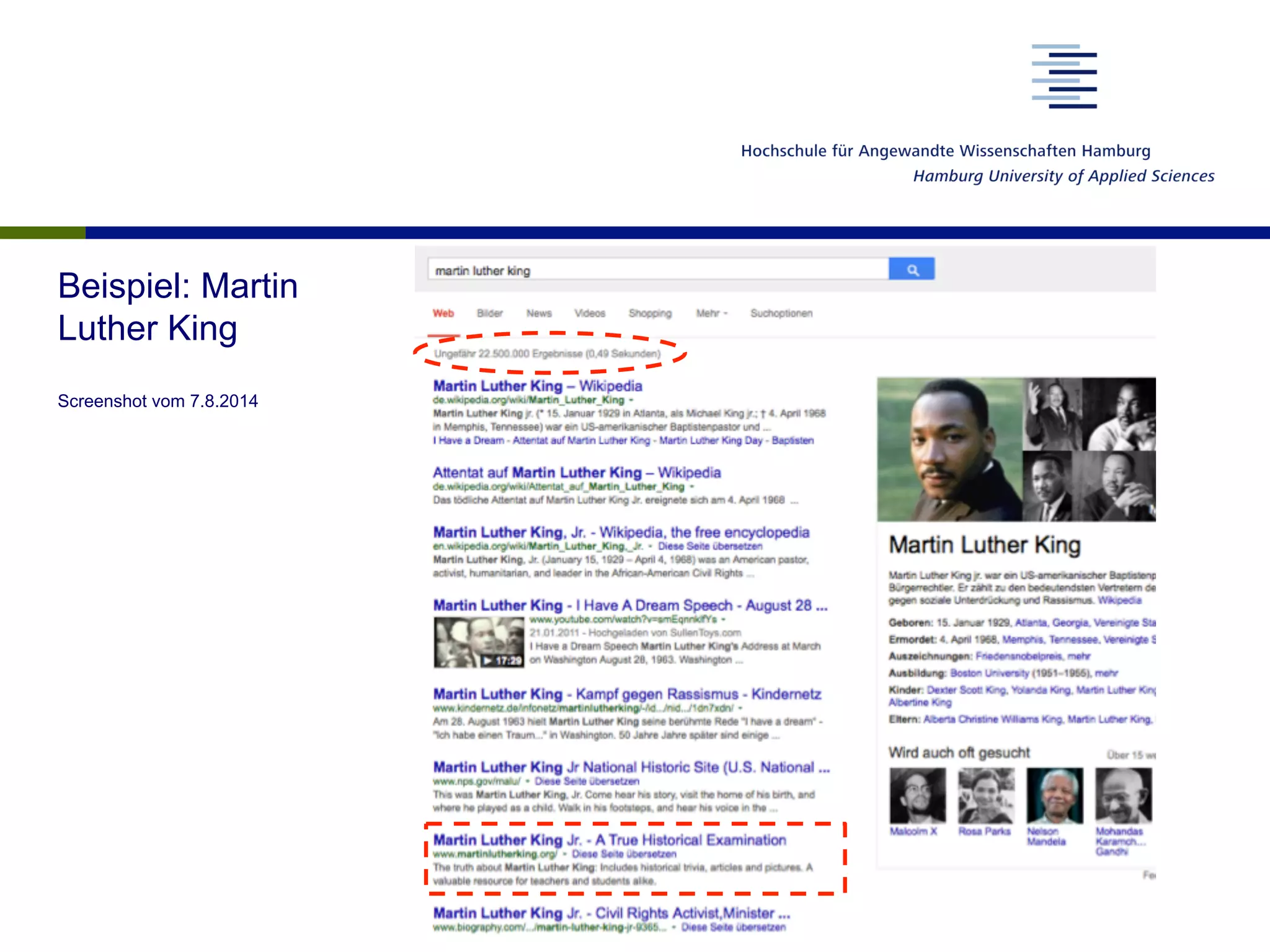













Das Dokument analysiert die Funktionsweise von Suchmaschinen und deren Auswirkungen auf das Nutzerverhalten sowie die Vertrauenswürdigkeit der Suchergebnisse. Es wird beschrieben, wie Nutzer Suchanfragen formulieren, welche Faktoren das Ranking von Suchergebnissen beeinflussen und wie Suchmaschinenergebnisse interpretiert werden. Abschließend wird auf die gesellschaftlichen Implikationen und den Forschungsbedarf hingewiesen, insbesondere in Bezug auf die algorithmische Interpretation von Inhalten und deren Einfluss auf die Meinungsbildung.





























































