Als PDF, PPTX herunterladen




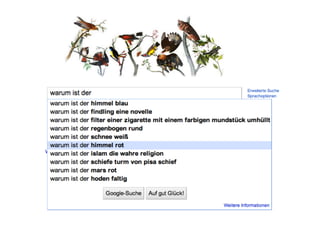
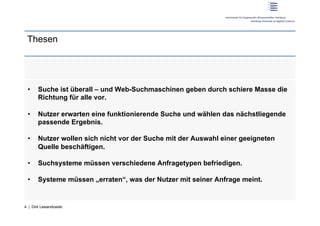
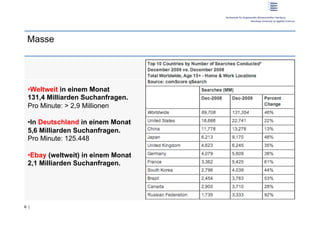





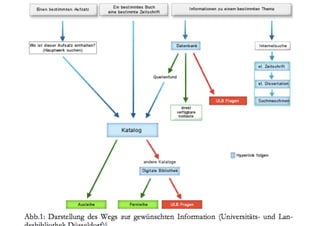
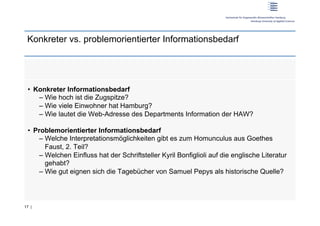

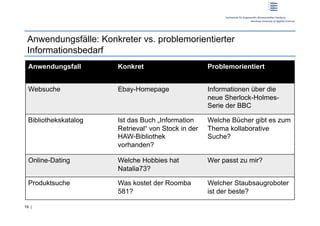

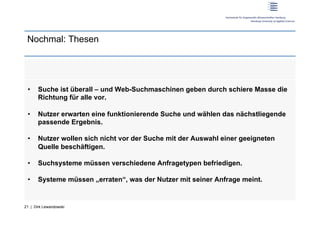

Der Workshop behandelt das Nutzerverhalten in der Web-Suche und deren Auswirkungen auf Informationssysteme. Prof. Dr. Dirk Lewandowski und Sonja Quirmbach präsentieren sowohl theoretische Grundlagen als auch praktische Anwendungen und diskutieren die Wichtigkeit von Suchmaschinen für Nutzer. Die Teilnehmer werden aktiv in Gruppenarbeiten und Diskussionen eingebunden, um effektive Suchsysteme zu entwickeln, die verschiedene Anfragetypen bedienen.














































