Downloaden Sie, um offline zu lesen




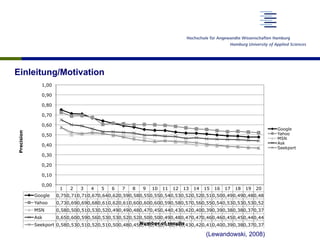
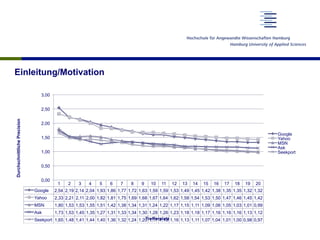










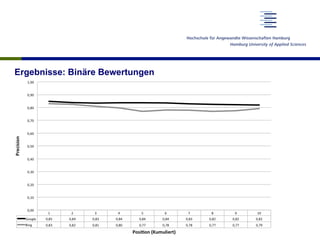
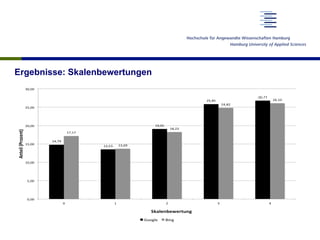
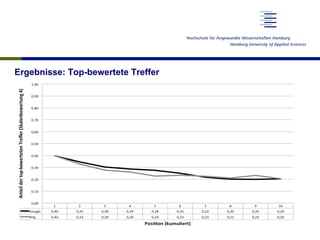






Das Dokument untersucht die Verwendung von Skalenbewertungen bei der Evaluierung von Suchmaschinen im Vergleich zu binären Bewertungen, um ein differenzierteres Bild der Suchmaschinenqualität zu gewinnen. Es zeigt auf, dass es trotz der hohen Aufwände keine signifikanten Unterschiede in der Bewertung der Trefferqualität gibt und empfiehlt, Skalenbewertungen aufgrund ihrer flexiblen Informativität zu verwenden. Die Forschung basiert auf einer soliden Datenbasis von über 19.000 Relevanzurteilen und umfasst mehrere testaufbauten und Diskussionen zu den Ergebnissen.



































