Als PDF, PPTX herunterladen





























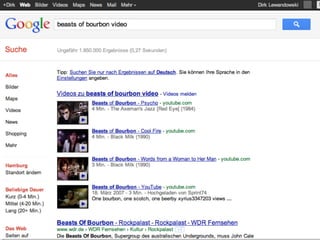
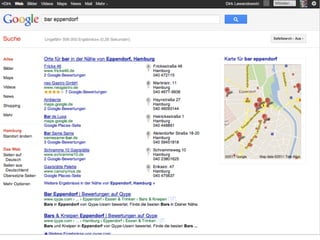
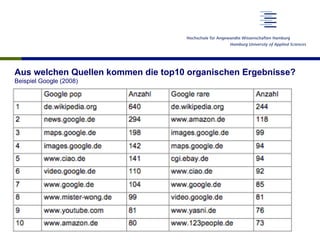




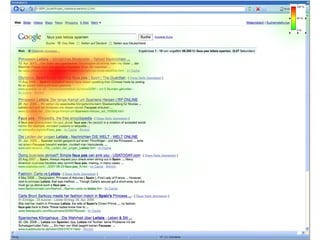
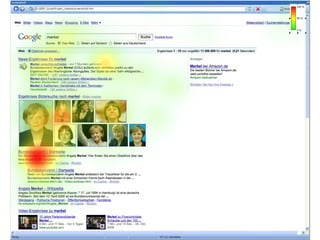
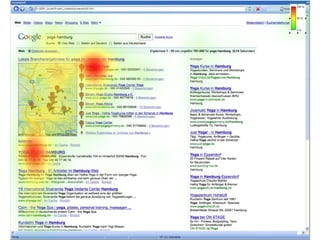




Das Dokument thematisiert den aktuellen Stand und die Entwicklungsperspektiven von Suchmaschinen, einschließlich der Marktposition, semantischer und sozialer Suchansätze sowie Fragen der Suchneutralität. Es wird aufgezeigt, wie semantische Annotationsmethoden und soziale Rankingfaktoren die Qualität und Relevanz von Suchergebnissen beeinflussen. Zudem wird auf die Herausforderungen hingewiesen, denen sich Inhaltsanbieter sowie Nutzer im Umgang mit Suchmaschinen gegenübersehen.































































