Downloaden Sie, um offline zu lesen






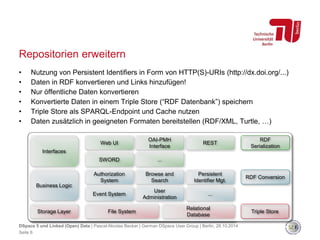



Das Dokument thematisiert die Einführung von DSpace 5, das Unterstützung für Linked Open Data bietet, einschließlich erweiterter REST-APIs und Batch-Importen. Es erläutert die Prinzipien des semantischen Webs und die Vorteile des Linked Data-Ansatzes gegenüber traditionellen Protokollen wie OAI-PMH für den Datenaustausch. Zudem wird darauf hingewiesen, dass DSpace 5.0 im Dezember 2014 veröffentlicht wird und eine starke Konfigurierbarkeit sowie Unterstützung für verschiedene RDF-Formate bietet.


























































































