Downloaden Sie, um offline zu lesen






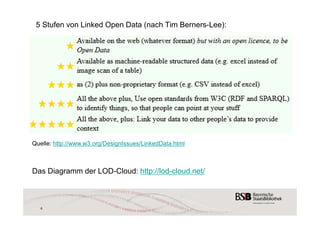














Das Dokument behandelt das Konzept des Linked Open Data (LOD) und dessen Anwendung in Bibliotheken, insbesondere beim RISM-OPAC. LOD ermöglicht es, offene Daten über URIs zu verknüpfen und unterstützt den Zugang zu Bibliothekskatalogen in einem vernetzten und semantischen Web. Weitere Themen sind die DINI AG KIM, Bibframe-Initiativen und die Wichtigkeit von RDF für die Strukturierung und Verknüpfung von Metadaten.












































































