Downloaden Sie, um offline zu lesen











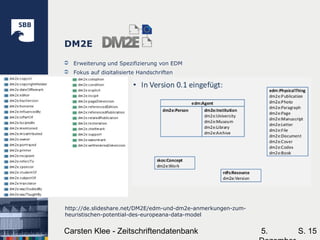




Das Dokument behandelt die Vorteile von Linked Data (LD) im Kontext von Digitalisierungsprojekten, insbesondere für Bibliotheken, und hebt die Möglichkeiten der flexiblen Datenverknüpfung sowie die Herausforderungen der Adaption hervor. Bibliotheken stehen vor der Aufgabe, ihre Daten in RDF zu veröffentlichen, während technologische Veränderungen und Datenschutzbedenken die Akzeptanz von LD behindern. Das Dokument skizziert zudem bestehende Standards wie OAI-ORE und das Europeana Data Model (EDM), die für die Digitalisierung von Ressourcen nützlich sind.










































