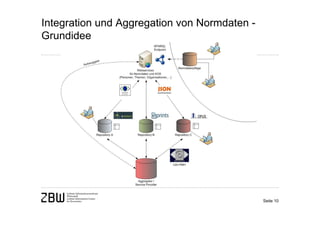
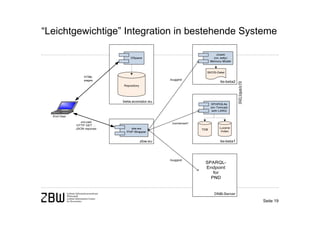
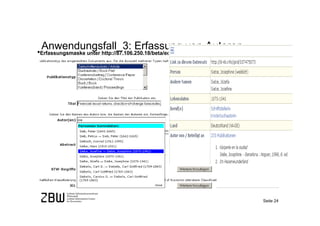
Das Dokument behandelt die Integration von Normdaten in Bibliotheksanwendungen unter Verwendung von Semantic Web-Technologien, um die Herausforderungen des verteilten Datenmanagements und die Schwierigkeiten bei der Aggregierung und Homogenisierung von Metadaten zu bewältigen. Es werden verschiedene Anwendungsfälle für die Nutzung von Normdaten, wie Verschlagwortung, Suchoptimierung und Autorenerfassung, vorgestellt. Zudem wird die Möglichkeit einer leichtgewichtigen Integration in bestehende Systeme thematisiert, um die Qualität der Metadaten und damit die angebotenen Dienste zu verbessern.




![Ausgangslage
Beispiel Repositorien und ihre Vernetzung
• Repositorien sind allgemein genutzte Erfassungs-/Retrieval-
/Verbreitungssysteme („Data Provider“), zumeist OSS und Community-
getrieben
• Zahlreiche Installationen an Hochschulen, Bibliotheken, Rechenzentren
• Vernetzungsinitiativen, z.B. OA-Netzwerk
• „OA-Netzwerk stellt Dienste auf der Basis von aggregierten Daten der DINI-
zertifizierten Repositorien bereit […] u.a. vorgesehen: Aggregation,
Harmonisierung und Ähnlichkeitsanalyse“
http://www.dini.de/fileadmin/workshops/oa-statistik-was-zaehlt/02_gerlach-
oas.pdf
• Einschlägige OSS-Repositoriensoftware (DSpace, EPrints, OPUS)
unterstützt derzeit noch nicht die Integration extern kontrollierter Normdaten
Seite 4](https://image.slidesharecdn.com/iknow2010definalneuescd2-110704081315-phpapp02/85/Integration-von-Normdaten-in-Bibliotheksanwendungen-auf-der-Basis-von-Semantic-Webservices-4-320.jpg)
















![•[1] http://wiki.dspace.org/index.php/Authority_Control_of_Metadata_Values
Literatur
•[2] http://minds.wisconsin.edu/handle/1793/31735
•[3] http://dsug09.ub.gu.se/index.php/dsug/dsug09/paper/view/22/3
•[4] http://subjectobject.net/2006/11/09/the-dspace-digital-repository-a-project-analysis/
•[5] http://code.google.com/p/dspace-agrisap/wiki/ThesaurusAddOn
•[6] http://edoc.hu-berlin.de/conferences/dc-2008/subirats-imma-199/PDF/subirats.pdf
•[7] http://www.jisc.ac.uk/media/documents/programmes/sharedservices/na
mes-phase-one-final-report,.pdf
•[8] http://idea.library.drexel.edu/bitstream/1860/3173/1/20070051011.pdf
•[9] http://ptsefton.com/blog/2006/06/06/the_affiliation_issue_in
_institutional_repository_software/
•[10] http://library.ust.hk/info/nac/nac-technical.html
•[11] http://www.seco.tkk.fi/publications/2009/kurki-hyvonen-onki-people-2009.pdf
•[12] http://journals.sfu.ca/archivar/index.php/archivaria/article/download/11883/12836
•[13] http://www.dini.de/fileadmin/workshops/oa-netzwerk-
juni2009/vernetzungstage_2009_malitz.pdf
Seite 26](https://image.slidesharecdn.com/iknow2010definalneuescd2-110704081315-phpapp02/85/Integration-von-Normdaten-in-Bibliotheksanwendungen-auf-der-Basis-von-Semantic-Webservices-26-320.jpg)









































































