Downloaden Sie, um offline zu lesen






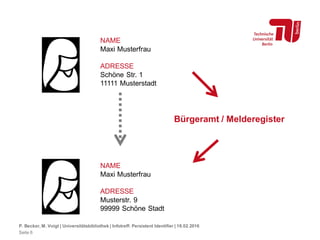
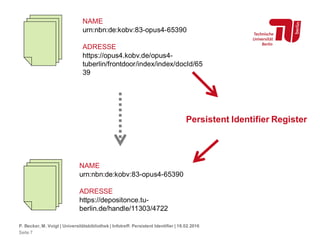











Das Dokument behandelt die Bedeutung und Funktion von persistent identifiers (PIs) im wissenschaftlichen Kontext, die dazu dienen, die Nachverfolgbarkeit elektronischer Ressourcen zu gewährleisten, da Internetadressen flüchtig sind. Verschiedene Systeme wie DOI, URN und Handle werden vorgestellt, wobei DOI als das am weitesten verbreitete System hervorgehoben wird. Weiterhin wird die Notwendigkeit solcher Identifiers für das wissenschaftliche Zitieren und die erfolgreiche Auffindbarkeit relevanter Dokumente betont.















































