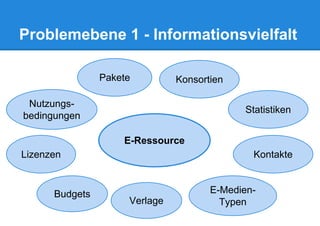
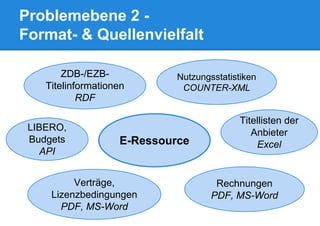
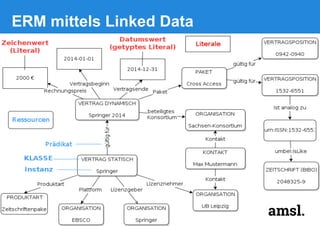
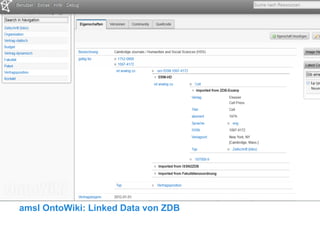
Das Dokument beschreibt die Entwicklung eines Electronic Resource Management Systems (ERM) für Bibliotheken unter Verwendung von Linked Data-Technologien, fokussiert auf die Integration heterogener Datenquellen und die Verknüpfung relevanter Informationen. Ziel ist die Schaffung eines flexiblen und anpassbaren Datenmodells, das die komplexen Geschäftsprozesse von elektronischen Medien abbildet. Das Projekt wird von der Universitätsbibliothek Leipzig in Zusammenarbeit mit anderen Institutionen durchgeführt und basiert auf den Prinzipien des Semantic Web.