Downloaden Sie, um offline zu lesen
















































![Quellenangaben Machen Zitate und Quellen auffindbar Entweder im Text [weniger empfehlenswert] ... 1) Franck, Norbert: Handbuch wissenschaftliches Arbeiten. Frankfurt am Main : Fischer-Taschenbuch-Verl. 2004, S.170 2) Franck a.a.O, S. 27 oder Kurztitelangaben in Fußnoten und vollständige Angabe im Literaturverzeichnis 1) s. N. Frank: Handbuch wissenschaftliches Arbeiten. 2004, S. 170 oder Kurzbelege im Text (Harvard-Methode) und vollständige Angaben im Literaturverzeichnis (Frank, 2003, S. 27) Vorgaben der Hochschule/Fakultät beachten!](https://image.slidesharecdn.com/ik1ws2011-12-110920041331-phpapp02/85/Ik1-ws-2011-12-49-320.jpg)











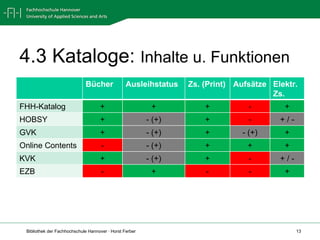
Das Dokument beschreibt ein Seminar zur Informationskompetenz an der Fachhochschule Hannover im Wintersemester 2011/12, das Themen wie Informationsbedarf, Recherchestrategien, Kataloge und Datenbanken umfasst. Es werden verschiedene Ressourcen und Techniken zur Informationsbeschaffung und -bewertung vorgestellt, einschließlich der Nutzung von Bibliothekskatalogen und Datenbanken. Zudem behandelt es rechtliche Aspekte wie Urheberrecht und Zitieren sowie die Bedeutung von Neuerscheinungen und aktuellen Informationen.
































































