Als PDF, PPTX herunterladen



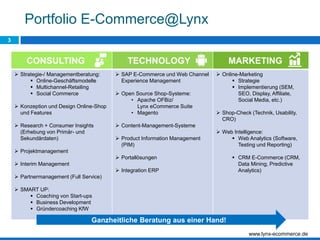



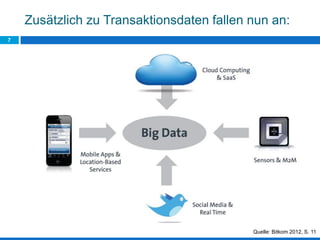
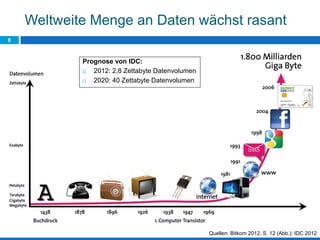


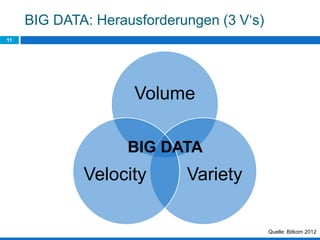






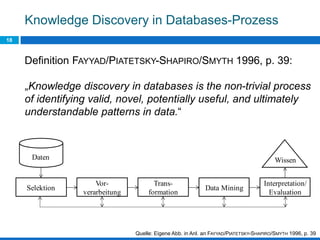

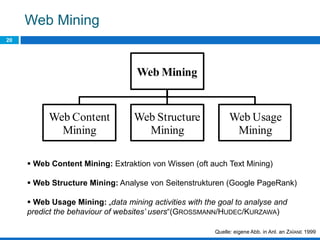
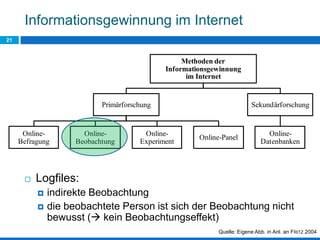
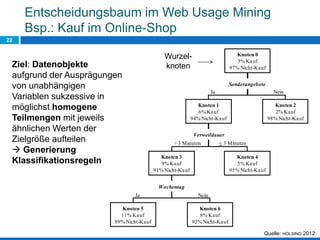


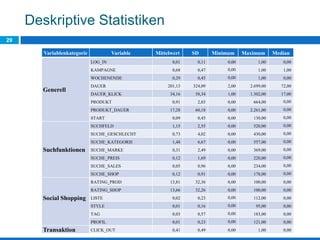
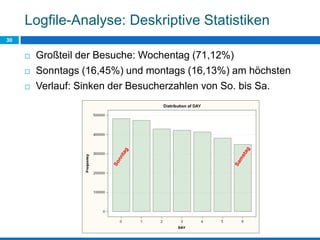
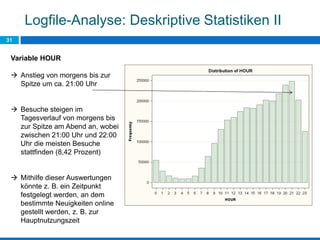


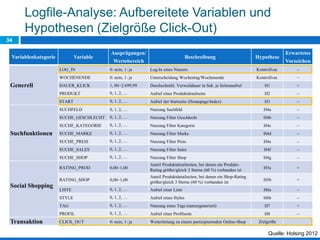
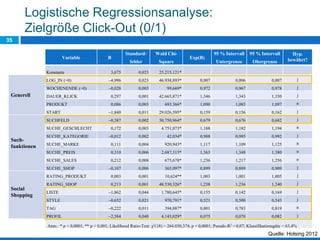
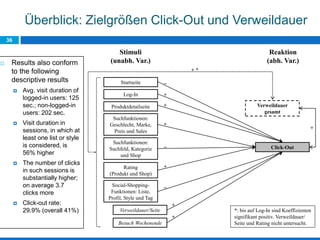
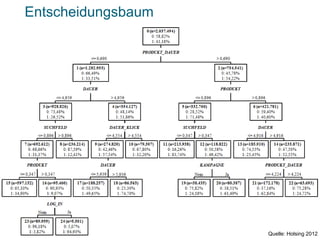
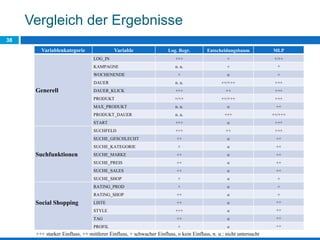





Das Dokument behandelt die Potenziale und Herausforderungen von Big Data und Web Mining im E-Commerce, insbesondere am Beispiel eines Online-Shopping-Portals. Es thematisiert die Definition von Big Data, Anwendungsfelder, den KDD-Prozess sowie Kritikpunkte an der Nutzung von großen Datenmengen. Zudem werden Methoden zur Analyse von Nutzerverhalten und Kaufentscheidungen in Social-Shopping-Communities vorgestellt.















































