


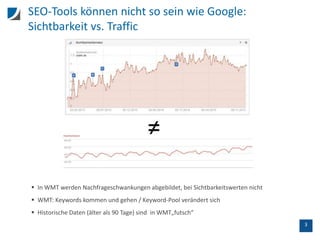
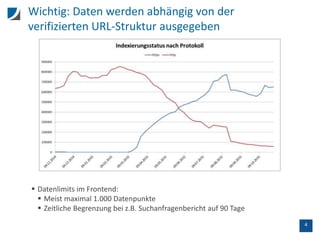
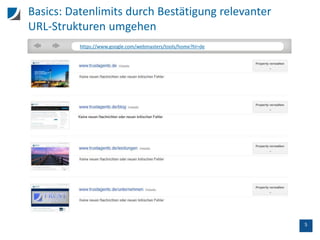

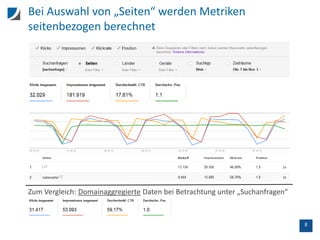
![7
Bye bye [not provided]: Seit Mai 2015 zeigt Google
in der Suchanalyse detailliertere Daten
Jede Dimension (z.B. Suchanfragen, Seiten) hat unterschiedliche Filter
Über „Länder“ sieht man seine Rankings in allen Ländern, in denen die
Website eine Impression hatte](https://image.slidesharecdn.com/1511-omx-google-search-console-stephan-czysch-trust-agents-151129114829-lva1-app6891/85/Google-Search-Console-Dateninterpretation-API-Stephan-Czysch-OMX-2015-7-320.jpg)
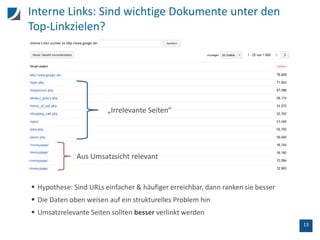
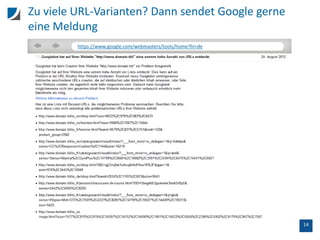
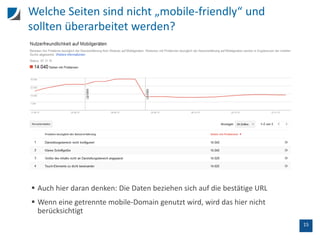
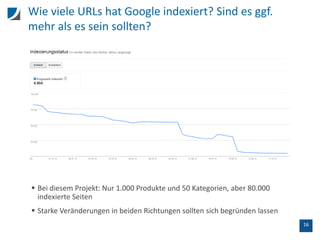





Der Vortrag behandelt die Unterschiede zwischen SEO-Tools und der Google Search Console, insbesondere hinsichtlich der Crawling-Methoden und Datenanalysen. Wichtige Aspekte sind die Limitierungen der Datenanzeige, die Handhabung von doppelten Titeln, sowie der Einfluss interner und externer Links auf das Ranking. Zudem wird die Nutzung der API zur Datenextraktion und die Prüfung der Mobilfreundlichkeit von URLs thematisiert.










































































