


























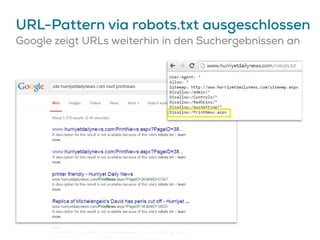
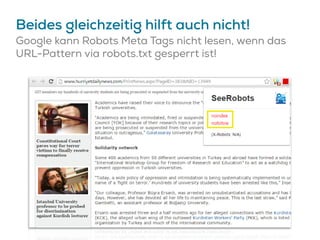


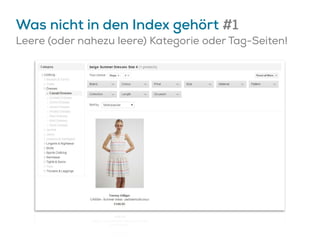
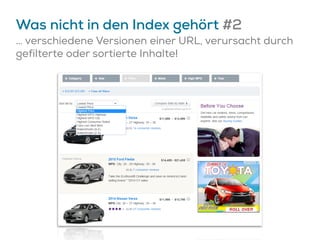
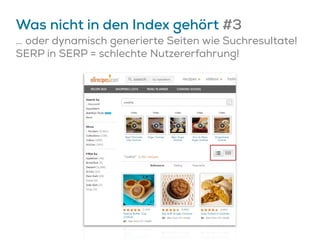













![Google könnte Canonicals ignorieren…
Verwendet Canonical Tags nicht als Entschuldigung
für schlechte Website-Architektur!
http://googlewebmastercentral.blogspot.de/2009/02/specify-your-canonical.html
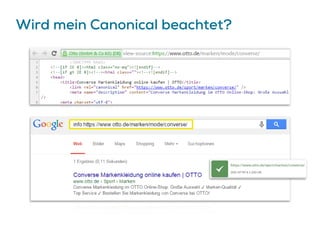
Is rel="canonical" a hint or a directive?
It's a hint that we honor strongly.
We'll take your preference into
account, in conjunction with other
signals, when calculating the most
relevant page […]](https://image.slidesharecdn.com/seoday-kln-2015grimmcrawlspace-151023054252-lva1-app6891/85/Crawl-Budget-Optimierung-SEOday-2015-61-320.jpg)










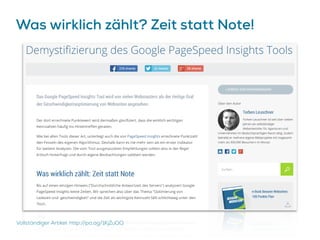

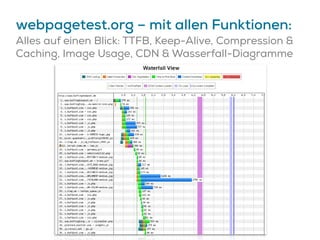


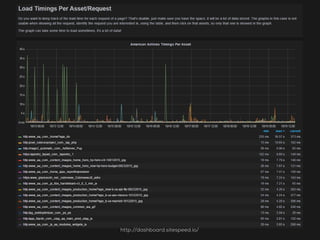














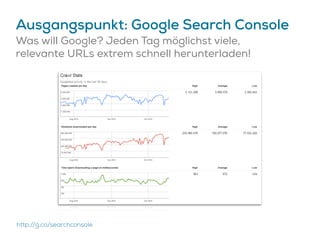
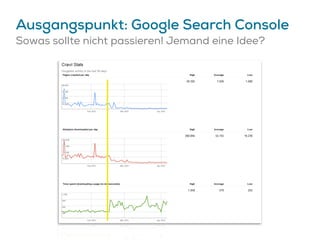
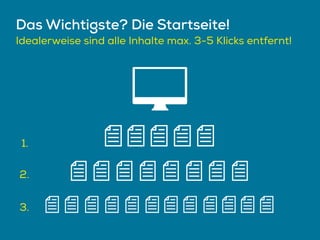
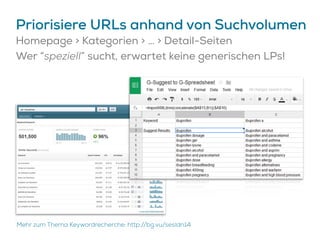
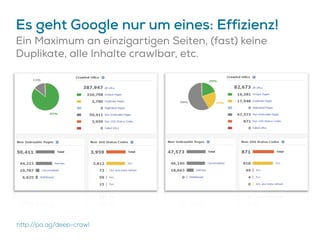
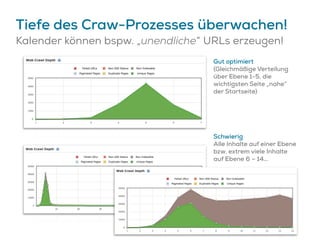
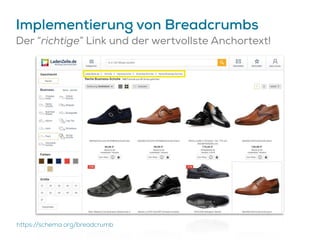
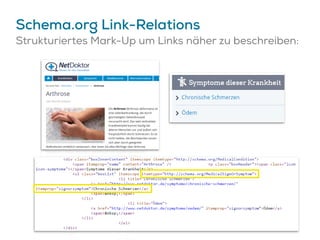
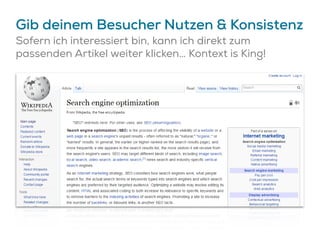
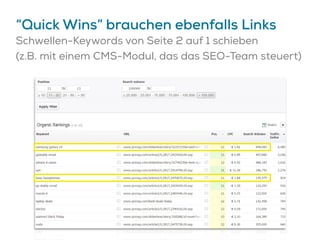
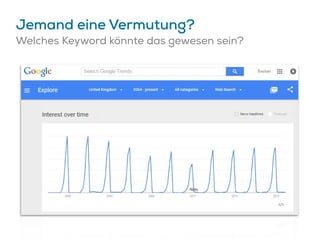
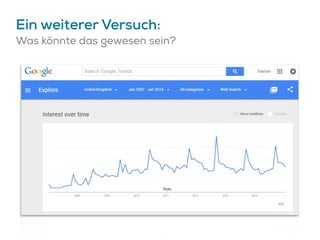
Das Dokument beschreibt Strategien zur Optimierung des Crawl-Budgets und der Crawl-Rate einer Domain, um sicherzustellen, dass Inhalte effizient und vollständig indexiert werden. Dabei werden Faktoren wie Linkprofil, Seitenarchitektur, Geschwindigkeit und Indexierungssteuerung durch Meta-Tags und Canonical-Tags hervorgehoben. Ziel ist es, Ressourcen effizient zu nutzen, Webseiten schnell und vollständig zu crawlen und damit die Sichtbarkeit in Suchmaschinen zu verbessern.





























![[DE] 8 häufige SEO-Fehler - Malte Landwehr](https://cdn.slidesharecdn.com/ss_thumbnails/maltelandwehr-haeufigeseo-fehler-151026103145-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

























































