


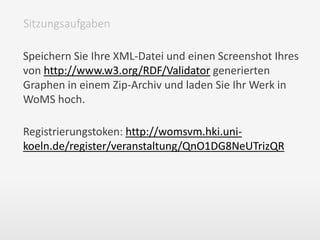





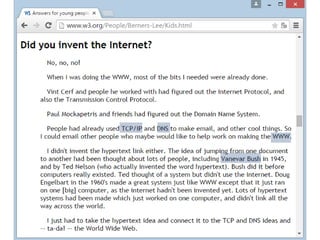





![„What‘s wrong with the web?“ – die Grenzen des WWW
I. „Wer ist Jan Wieners?“
Suchanfrage: Wieners
[Wer], [ist] weniger relevante Suchterme
tf-idf-maß
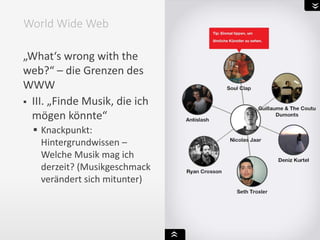
World Wide Web](https://image.slidesharecdn.com/bit-sosem2016-wienerssitzung-08semantic-web-160519131734/85/Bit-sosem-2016-wieners-sitzung-08_semantic-web-21-320.jpg)












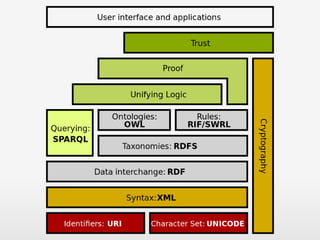





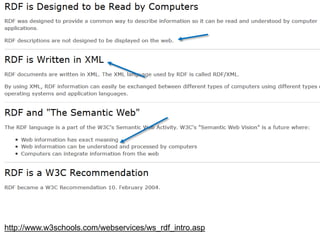


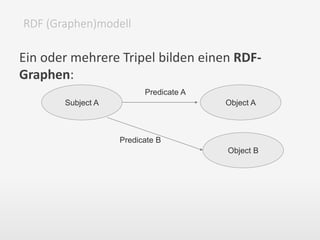


















Das Dokument behandelt das Semantic Web und Mikroformate, insbesondere RDF und FOAF, zur Wissensrepräsentation im World Wide Web. Es beschreibt die Prinzipien hinter RDF, die Bedeutung von Tripeln (Subjekt, Prädikat, Objekt) und bietet praktische Anwendungen zur Beschreibung von Personen und deren Beziehungen. Weiterhin wird auf die Grenzen des WWW und die Herausforderungen bei der Interpretation natürlicher Sprache eingegangen.






























































