Downloaden Sie, um offline zu lesen



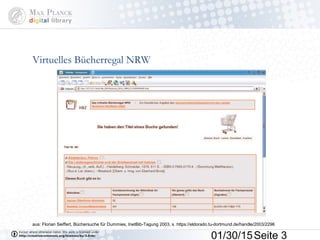
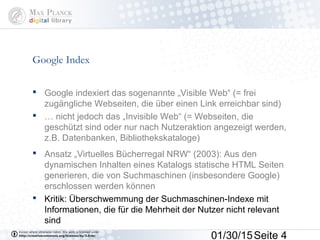


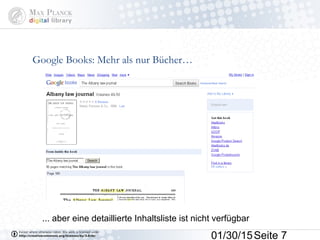
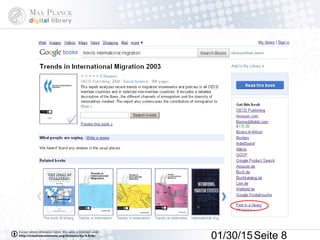
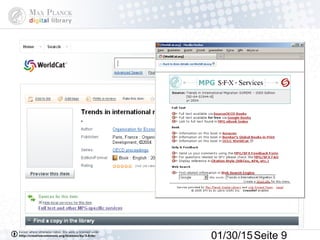
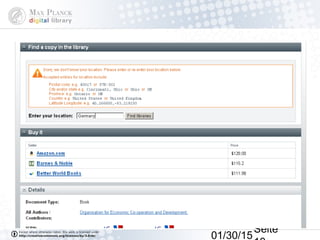
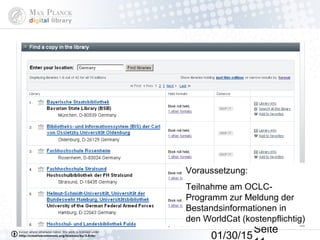

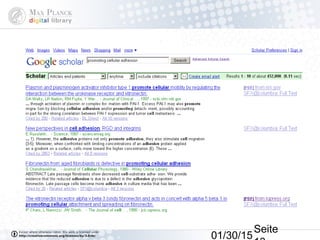
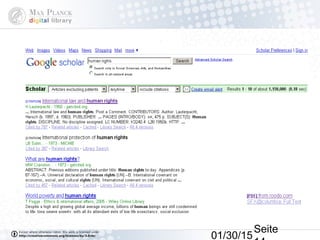





Das Dokument behandelt die Indexierung von Webseiten durch Google, wobei zwischen dem 'visible web' und dem 'invisible web' unterschieden wird. Es beschreibt den Ansatz des 'virtuellen Bücherregals NRW' zur Verbesserung der Auffindbarkeit von Bibliothekskatalogen sowie die Rolle von Google Books und Google Scholar in der Bereitstellung und Indizierung von wissenschaftlichen Inhalten. Kritisch wird der Aufwand zur Meldung von Beständen und die Herausforderung der Überflutung von Suchmaschinenergebnissen thematisiert.























![Lizleidis[1]22](https://cdn.slidesharecdn.com/ss_thumbnails/lizleidis122-130408175154-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















