Als PDF, PPTX herunterladen










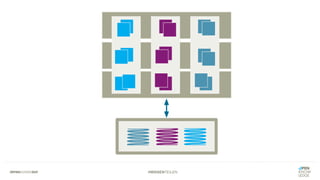
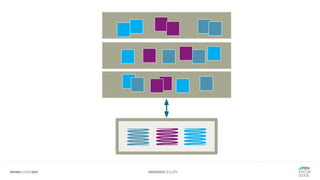














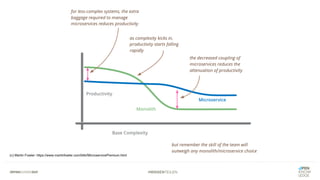










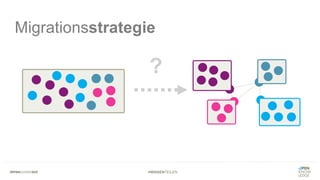











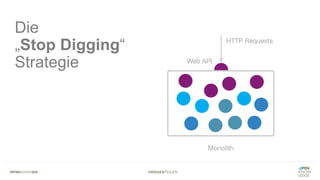












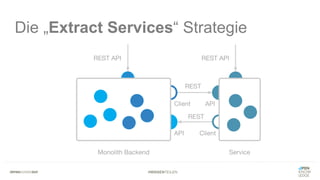




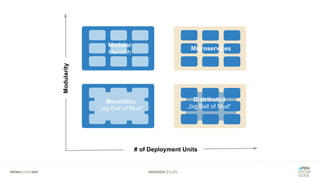















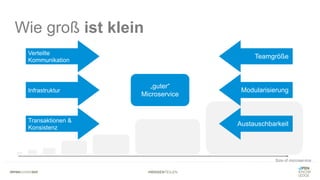







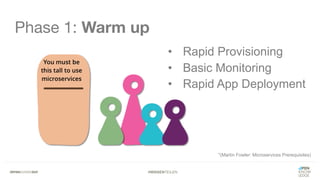
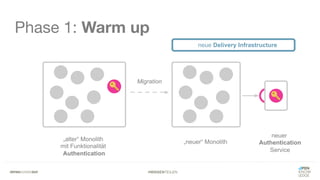










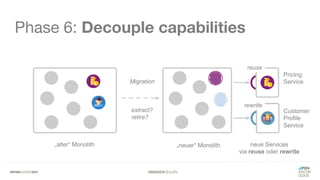

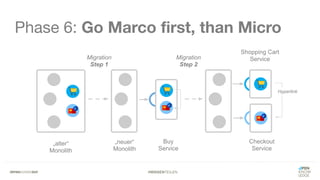

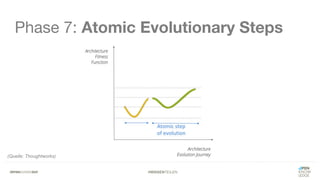
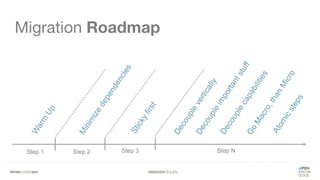









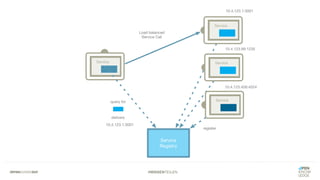
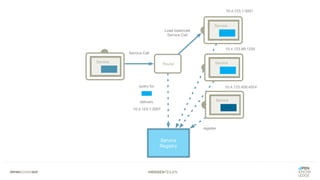




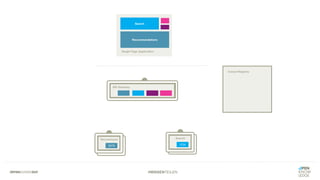



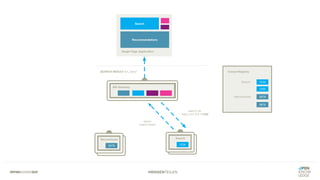









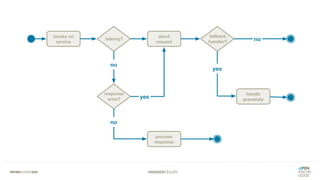



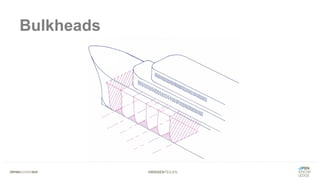
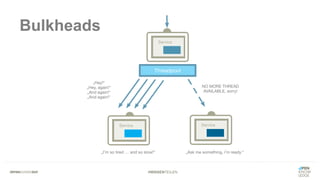
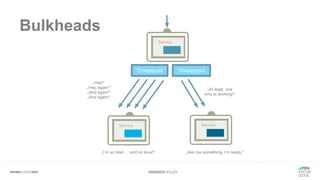




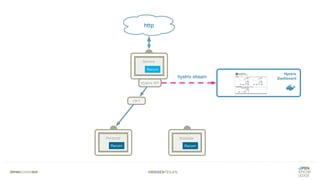
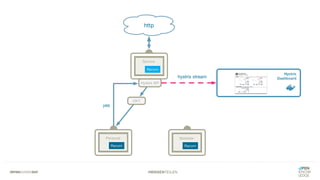

























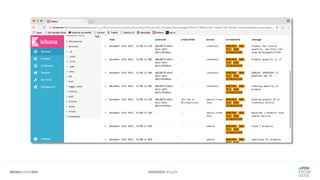











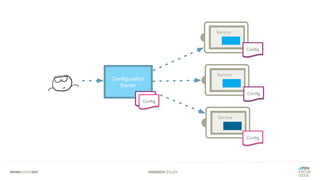










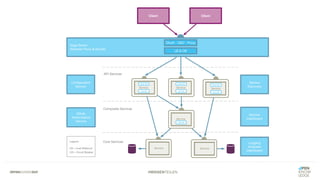















Das Dokument bietet einen umfassenden Leitfaden zur Migration von Monolithen zu Mikroservices, einschließlich Strategien wie 'Big Bang', 'Strangler Application' und verschiedene Stufen der Entkopplung. Es werden grundlegende Prinzipien wie Single Responsibility und hohe Kohäsion behandelt, sowie Herausforderungen und Lösungen im Zusammenhang mit Microservices, wie Service Discovery und Fehlertoleranz. Zudem wird die Bedeutung einer strukturierten Migrationsstrategie und des Designs von Mikroservices hervorgehoben.



































































