Als PDF, PPTX herunterladen







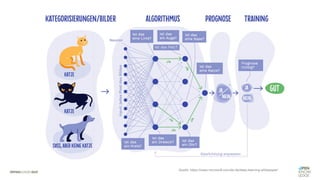
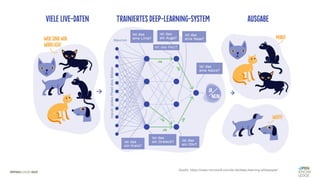

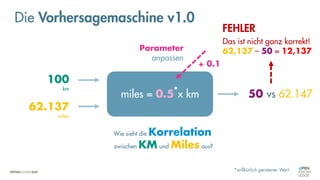
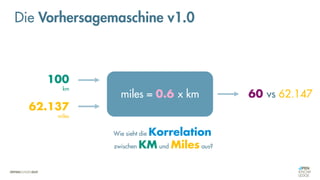
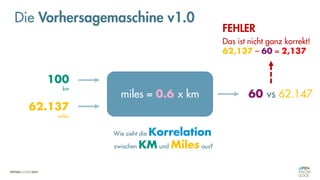
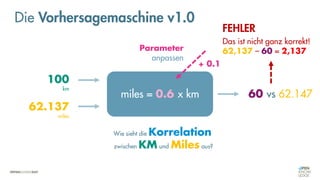
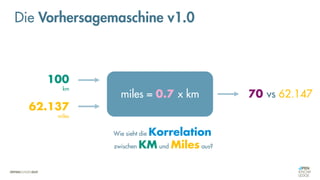
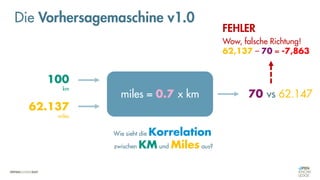
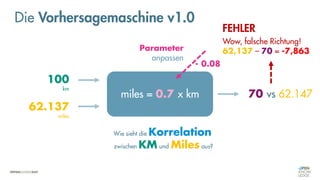
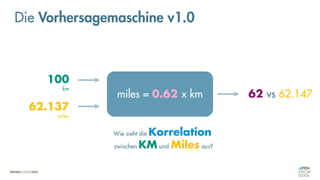
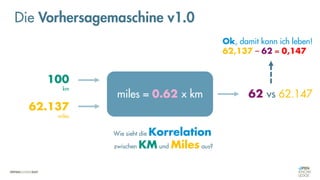
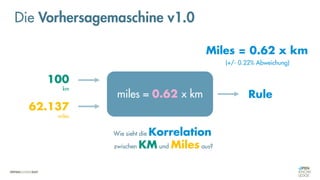
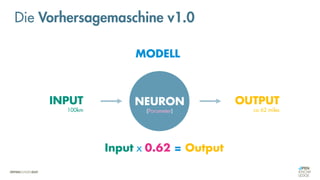





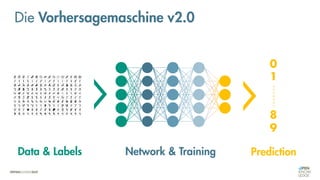
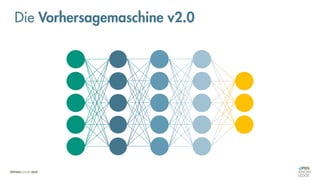
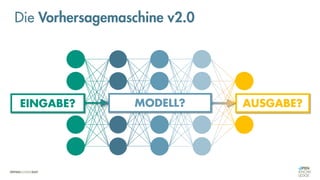
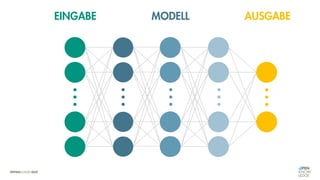
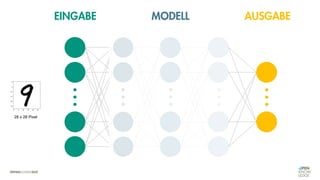
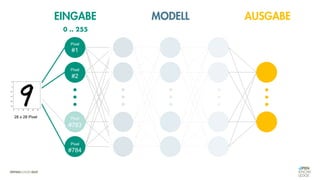
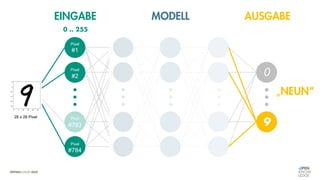
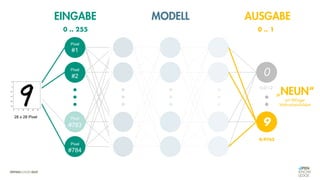
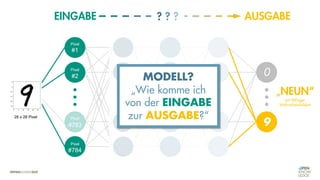
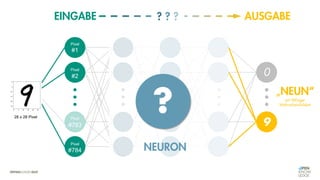
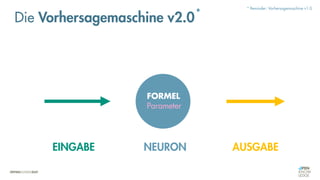
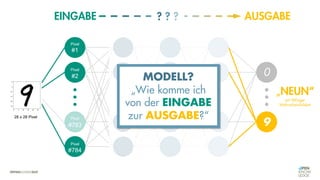
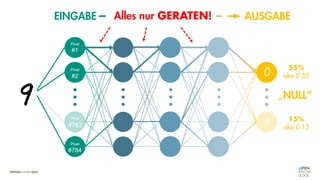
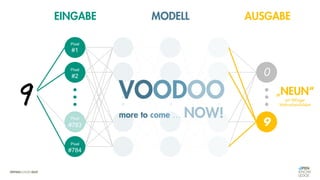
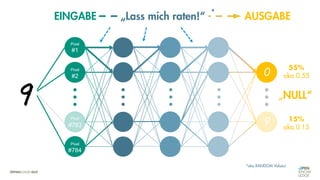
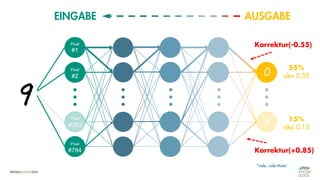
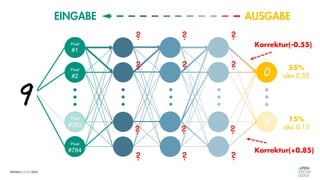
![Es besteht eine „unbekannte“ Relation zwischen einer
EINGABE und der zugehörigen AUSGABE.
Ein MODELL „schätzt“ diese Relation […] ab.
Die Vorhersagemaschine v2.0](https://image.slidesharecdn.com/seneuralnetworksfinal-220202103913/85/It-s-not-Rocket-Science-Neuronale-Netze-40-320.jpg)
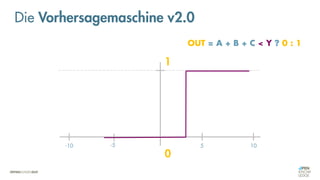
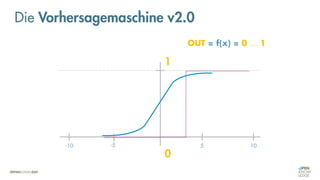
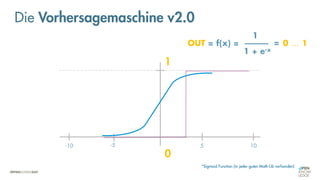
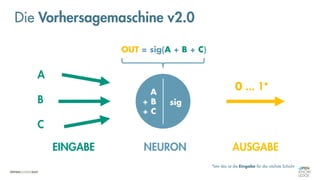

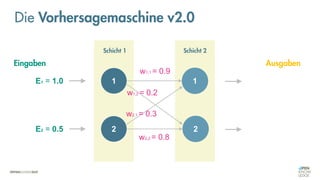
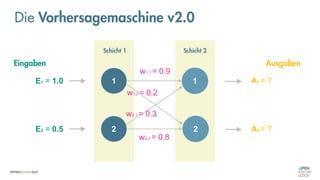
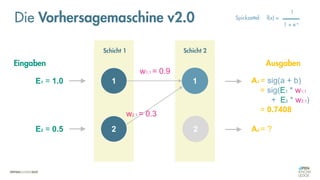
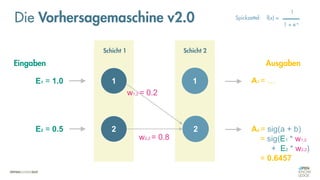

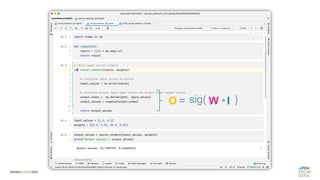



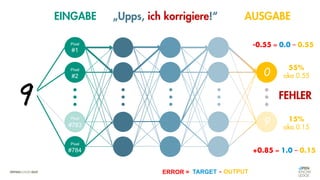




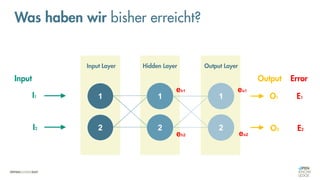


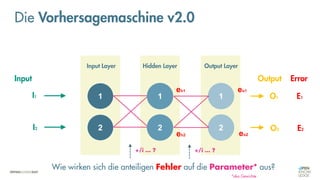



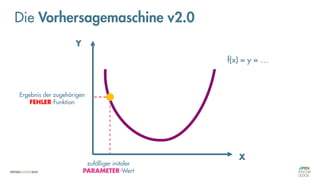
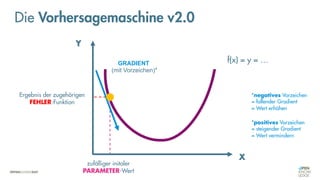
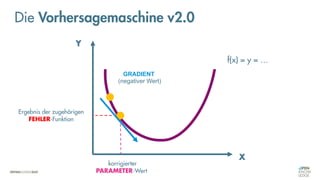
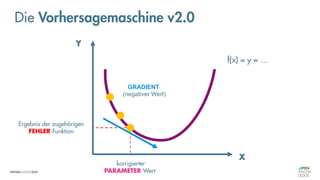

![Was zeichnet eine gute FEHLER-Funktion aus?
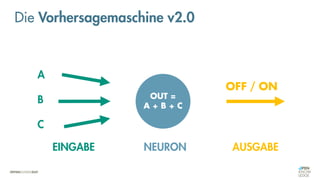
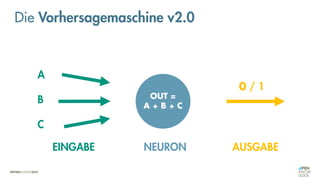
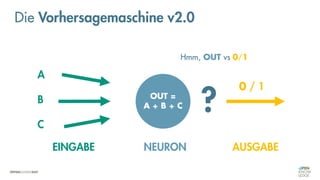
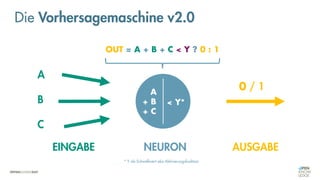
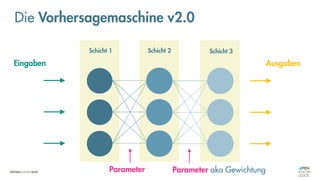
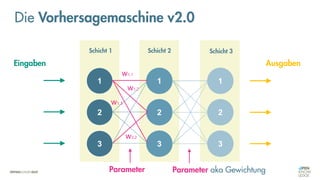
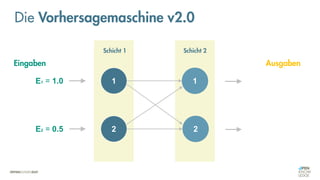
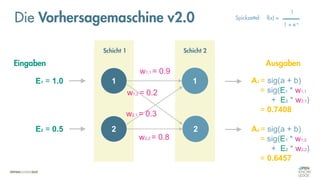
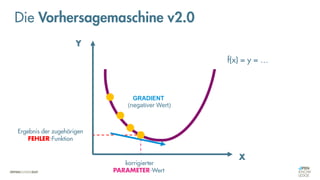
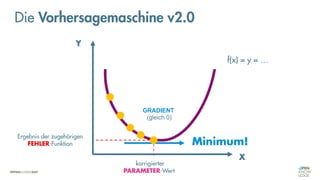
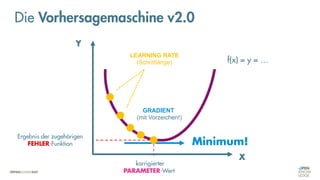
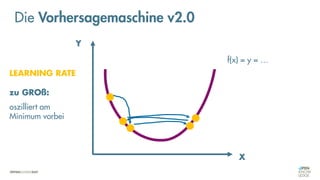
Die Vorhersagemaschine v2.0
Soll - Ist [Soll – Ist]
1.0
0.4
0.8
1.0
0.5
0.7
0.0 0.0
0.1 0.1
-0.1 0.1
0.0 0.2
Output Sollwert
Summe](https://image.slidesharecdn.com/seneuralnetworksfinal-220202103913/85/It-s-not-Rocket-Science-Neuronale-Netze-102-320.jpg)
![Was zeichnet eine gute FEHLER-Funktion aus?
Die Vorhersagemaschine v2.0
Soll - Ist [Soll – Ist] (Soll – Ist)2
1.0
0.4
0.8
1.0
0.5
0.7
0.0 0.0 0.00
0.1 0.1 0.01
-0.1 0.1 0.01
0.0 0.2 0.04
Output Sollwert
Summe](https://image.slidesharecdn.com/seneuralnetworksfinal-220202103913/85/It-s-not-Rocket-Science-Neuronale-Netze-103-320.jpg)


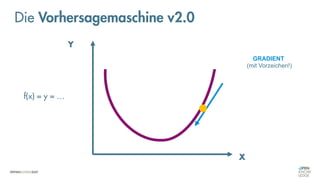
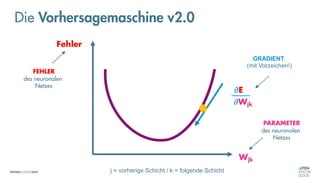




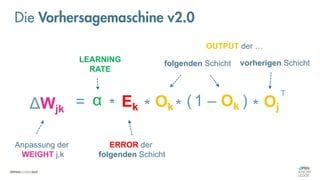





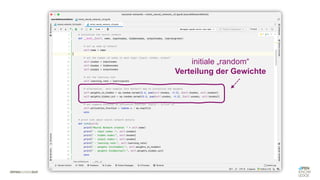
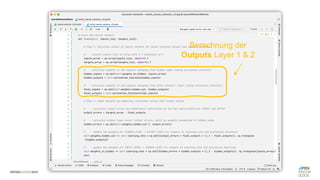
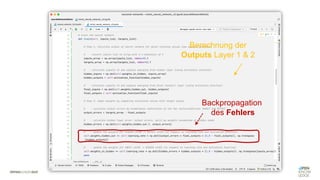
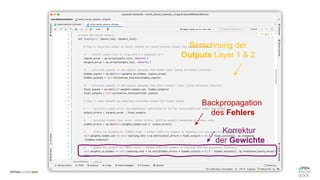

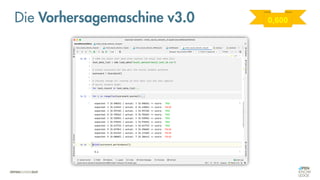


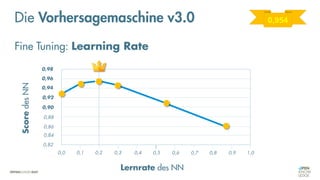
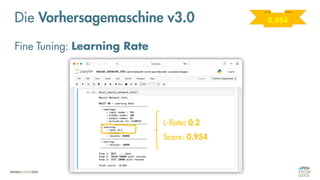

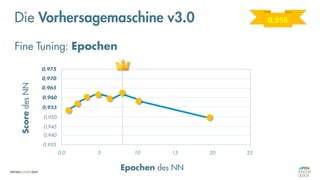
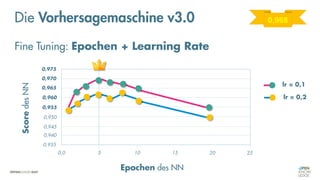
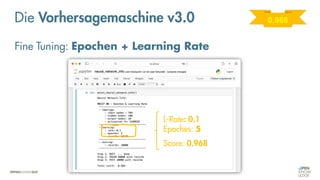

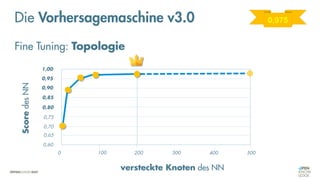
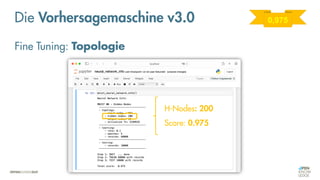
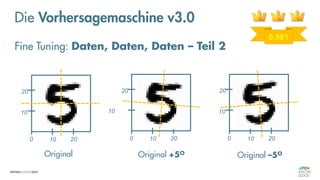






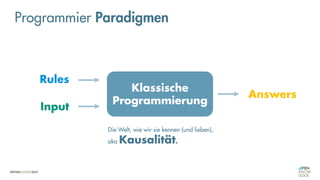
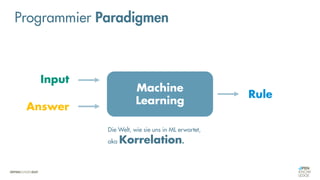
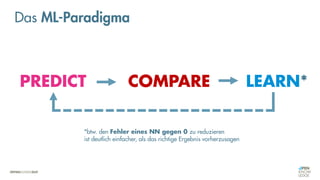
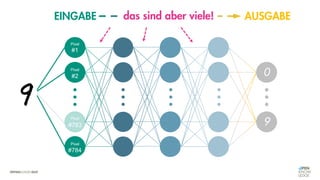
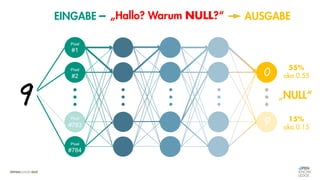
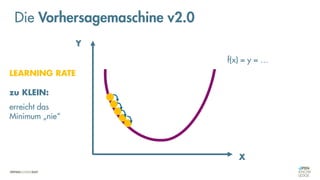
Das Dokument behandelt die Grundlagen neuronaler Netze und deren Anwendung im Bereich der künstlichen Intelligenz. Es erklärt die unterschiedlichen Typen von KI und Machine Learning, einschließlich Deep Learning, und beschreibt, wie neuronale Netze zur Vorhersage und Fehlerkorrektur in Modellen verwendet werden. Zudem wird behandelt, wie unbekannte Beziehungen zwischen Ein- und Ausgaben durch Anpassung von Parametern geschätzt werden können.


































