Als PDF, PPTX herunterladen



















![#WISSENTEILEN
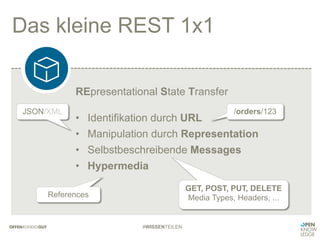
REST & Hateoas
// Response with link header for HYPERMEDIA navigation
// after calling „POST .../orders/ <order ... />“
HTTP/1.1. 201 Created
[various other headers]
Link: <.../orders/1234>; rel=„cancel“
<.../orders/1234>; rel=„update“,
<.../orders/1234>; rel=„delete“,
<.../payment/1234>; rel=„pay“](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-21-320.jpg)
![#WISSENTEILEN
REST & Hateoas
// Response with link header for HYPERMEDIA navigation
// after calling „GET .../orders?page=10“
HTTP/1.1. 206 Partial Content
[various other headers]
Link: <.../orders?page=1>; rel=„first“
<.../orders?page=9>; rel=„next“,
<.../orders?page=11>; rel=„prev“,
<.../orders?page=17>; rel=„last“](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-22-320.jpg)

![#WISSENTEILEN
REST & Hateoas
// Response with link header for HYPERMEDIA navigation
// after calling „GET .../orders?page=10“
HTTP/1.1. 206 Partial Content
[various other headers]
Link: <.../orders?page=1>; rel=„first“
<.../orders?page=9>; rel=„next“,
<.../orders?page=11>; rel=„prev“,
<.../orders?page=17>; rel=„last“
Wait, does this
make sense?](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-24-320.jpg)






![#WISSENTEILEN
REST & Queries
// FILTERING: List of paid orders (2015-12-20)
// Common Style
GET /orders?date=20151220&status=payed HTTP/1.1
[various other headers]](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-31-320.jpg)
![#WISSENTEILEN
REST & Queries
// FILTERING: Details of order 3: product, date & status
// Facebook Style
GET /orders/3?fields=product,date,status HTTP/1.1
[various other headers]
GET /orders/3?fields=item.product,date,status HTTP/1.1
[various other headers]
// LinkedIn Style
GET /orders/3:(product, date, status) HTTP/1.1
[various other headers]](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-32-320.jpg)
![#WISSENTEILEN
REST & Queries
// FILTERING: Details of order 3
// without date, status
GET /orders/3?exclude=date,status HTTP/1.1
[various other headers]
// predefined payload (compact = product, date, status)
GET /orders/3?style=compact HTTP/1.1
[various other headers]
BTW: what does
„compact“ mean?](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-33-320.jpg)











































![#WISSENTEILEN
GraphQL
// A very simple GraphQL schema example
type Character {
name: String! // non nullable
appearsIn: [Episode]! // array of ..., non nullable
}
type Starship {
id: ID! // unique ID
name: String!
length(unit: LengthUnit = METER): Float // parameter
}](https://image.slidesharecdn.com/jenseitsvonrestrequestresponse-161123152652/85/Web-APIs-jenseits-von-REST-Request-Response-79-320.jpg)






















































Das Dokument behandelt die Prinzipien und Best Practices der REST-Architektur sowie deren Anwendung in Web-APIs, einschließlich der Bedeutung von URIs, HTTP-Methoden und Statuscodes. Zudem wird das Konzept von HATEOAS und die Unterschiede zu GraphQL beschrieben, wobei letzteres flexiblere Abfragen und eine effizientere Nutzung von API-Ressourcen ermöglicht. Es werden Beispiele und Tipps zur Implementierung von RESTful APIs gegeben, um komplexe Anforderungen und Abfragen zu behandeln.



































































