Als PDF, PPTX herunterladen









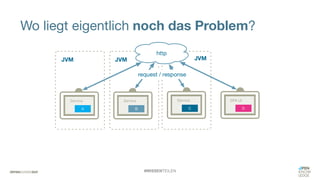





















































































Das Dokument diskutiert die Herausforderungen der Enterprise-Java-Entwicklung in Zeiten von Cloud- und Serverless-Architekturen und kritisiert die Limitierungen von Java EE hinsichtlich Speicherbedarf, Startup-Zeiten und Flexibilität. Es werden alternative Ansätze wie Javalin, Meecrowave und Eclipse MicroProfile vorgestellt, um die Effizienz und Modularität in der Entwicklung von Microservices zu verbessern. Zudem wird Quarkus als eine innovative Lösung hervorgehoben, die auf eine optimierte Performance und Unterstützung führender APIs abzielt, um die Anforderungen einer modernen Cloud-nativen Umgebung zu erfüllen.


























































