Als PDF, PPTX herunterladen























![Die Spezialisten (insb. graphartige Daten)
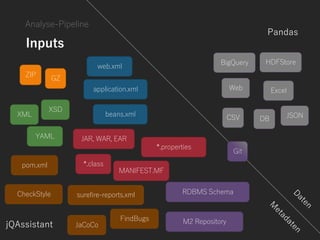
Analyse-Pipeline
Framework zur statischen
Architektur- und Code-
Analyse
Graph-Datenbank
[:SPEICHERT_IN]](https://image.slidesharecdn.com/nachvollziehbaredatengetriebeneautomatisierteanalysendersoftwareentwicklungdevelopercamp2017-170517170020/85/Nachvollziehbare-datengetriebene-automatisierte-Analysen-der-Softwareentwicklung-DeveloperCamp2017-26-320.jpg)



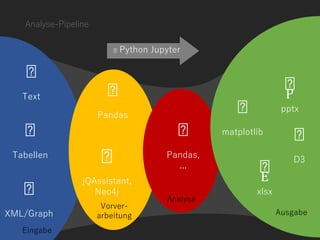







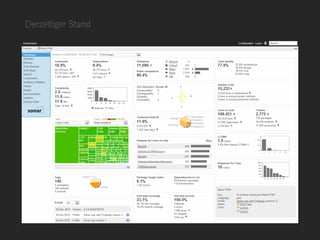
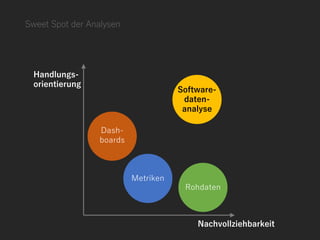
Die Präsentation thematisiert datengetriebene und automatisierte Analysen in der Softwareentwicklung, um klare Erkenntnisse über Probleme wie fehlschlagende CI-Bauten und ineffiziente Datenbankaufrufe zu gewinnen. Sie betont die Notwendigkeit von Nachvollziehbarkeit und Automatisierung in der Datenanalyse und bietet Lösungen, um kontinuierliches Lernen zu fördern und die Entscheidungsfindung zu verbessern. Verschiedene Ansätze zur strukturierten Analyse und der Einsatz von Tools werden vorgestellt, um Herausforderungen in der Softwareentwicklung zu meistern.





![Philosophy screws it all up (Pecha Kucha) [Java Forum Stuttgart 2017]](https://cdn.slidesharecdn.com/ss_thumbnails/philosophyscrewsitallup-pechakuchajfs2017-170709191249-thumbnail.jpg?width=640&height=640&fit=bounds)
![Architektur und Code im Einklang [JUG Nürnberg]](https://cdn.slidesharecdn.com/ss_thumbnails/architekturundcodeimeinklangjavausergroupnrnberg-170628202226-thumbnail.jpg?width=640&height=640&fit=bounds)
![Architektur und Code im Einklang [DeveloperCamp 2017]](https://cdn.slidesharecdn.com/ss_thumbnails/architekturundcodeimeinklangdevelopercamp2017-170518105432-thumbnail.jpg?width=640&height=640&fit=bounds)



















