Downloaden Sie, um offline zu lesen






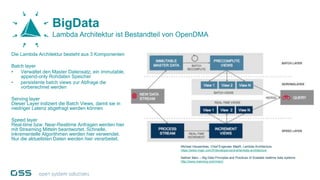



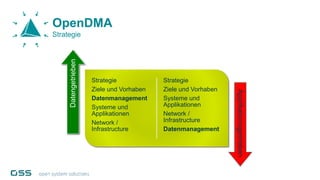
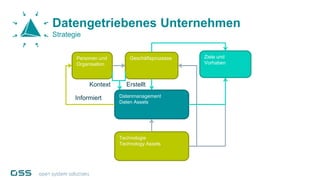
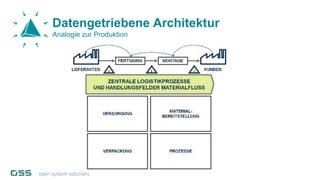
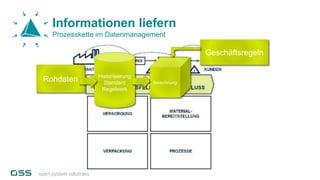
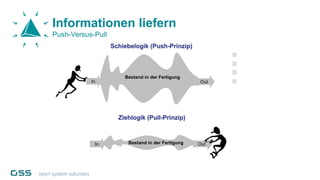


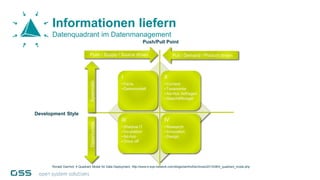

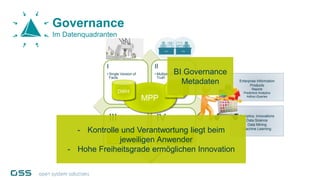



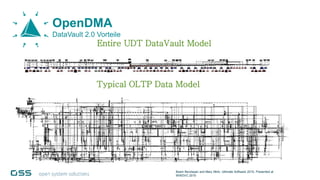




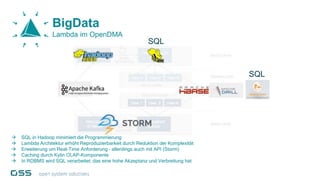
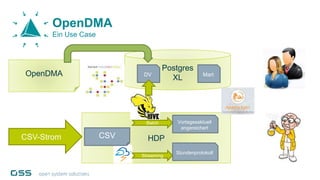



Open Data Management Automation (opendma) ist eine moderne Plattform für Datenmanagement in Data Warehouses und Big Data Analysen, die sich auf Automatisierung, Datenarchitektur und Data Vault fokussiert. Sie ermöglicht eine flexible, skalierbare Verarbeitung großer Datenmengen und bietet Lösungen für sowohl strukturierte als auch unstrukturierte Daten, einschließlich einer Datenarchitektur, die auf der Lambda-Architektur basiert. Mit einem besonderen Schwerpunkt auf Cloud-Kompatibilität und Automatisierung zielt opendma darauf ab, die Effizienz im Datenmanagement zu steigern.

























































